
Prompt Creation
Prerequisites
Before starting, ensure you have:
Unlock the full power of Freeplay by setting up your prompts directly in our UI. This approach gives you access to easy prompt management including version control, collaborative editing, and comprehensive evaluation tools.
Why Start from the UI?
Starting from the UI unlocks powerful features:
- Version Control: Track every prompt iteration with full history
- Collaborative Editing: Enable non-technical team members to test, iterate and deploy prompts
- Interactive Playground: Test prompts in real-time with different models
- Model-Graded Evaluations: Monitor quality with customizable metrics
- Environment Management: Deploy different versions to dev/staging/prod
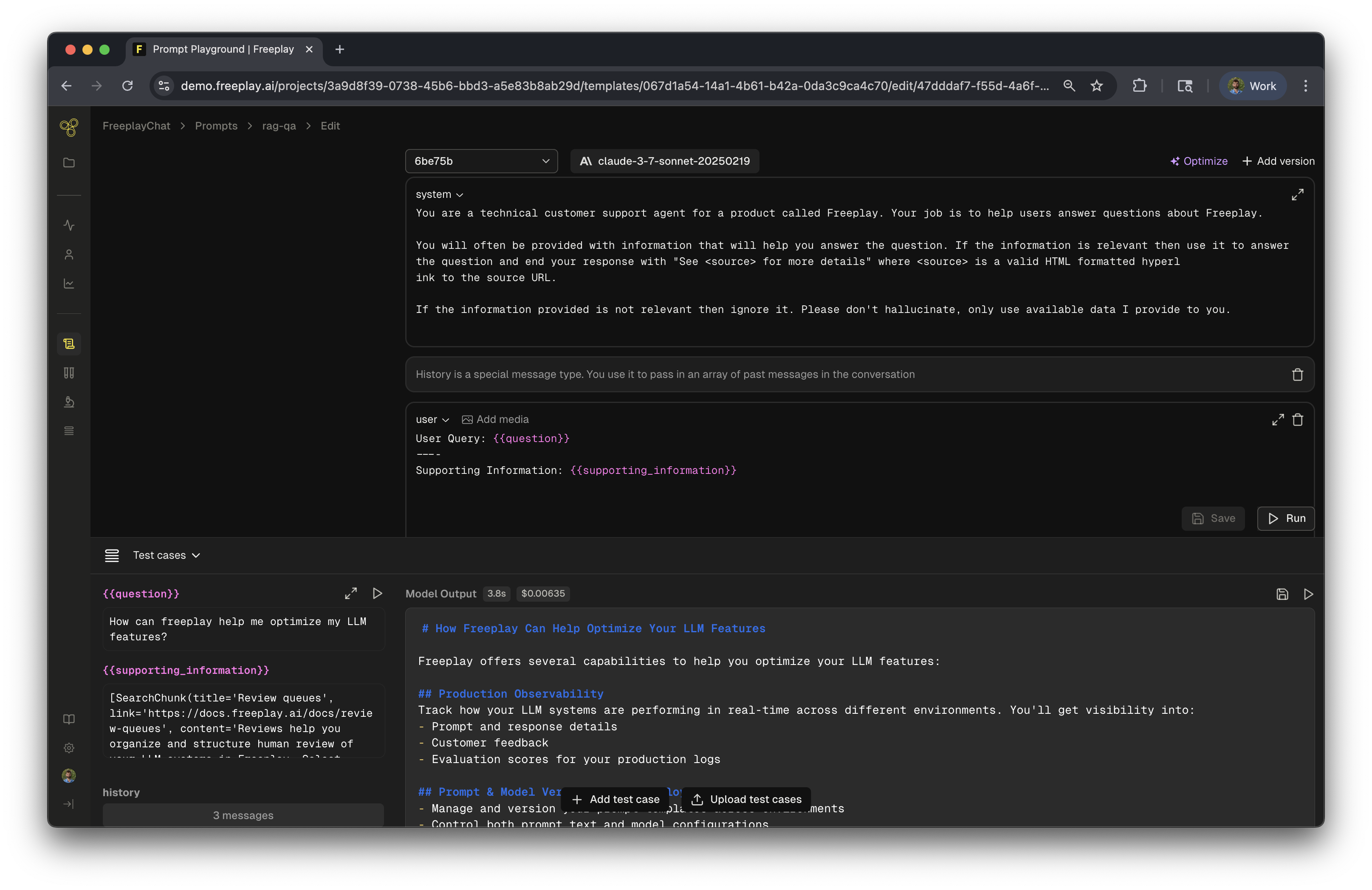
Step 1: Create Your Prompt Template
After creating your project, you'll be prompted to create a new Prompt Template. Let's walk through building a template for a RAG (Retrieval-Augmented Generation) application.
Select Your Model
Start by choosing your LLM and configuring its parameters:
For this example, we'll use gpt-4 with default settings, but you can choose from any supported provider.
Design Your Template
Prompt Templates are reusable structures with dynamic content. Use Input Variables (denoted with {{variable}}) for content that changes at runtime. Input Variables are also targetable for evaluations!
Here's our RAG template structure:
- System Message: High-level instructions for the model
- Input Variables:
{{question}}- The user's query{{supporting_information}}- Retrieved context
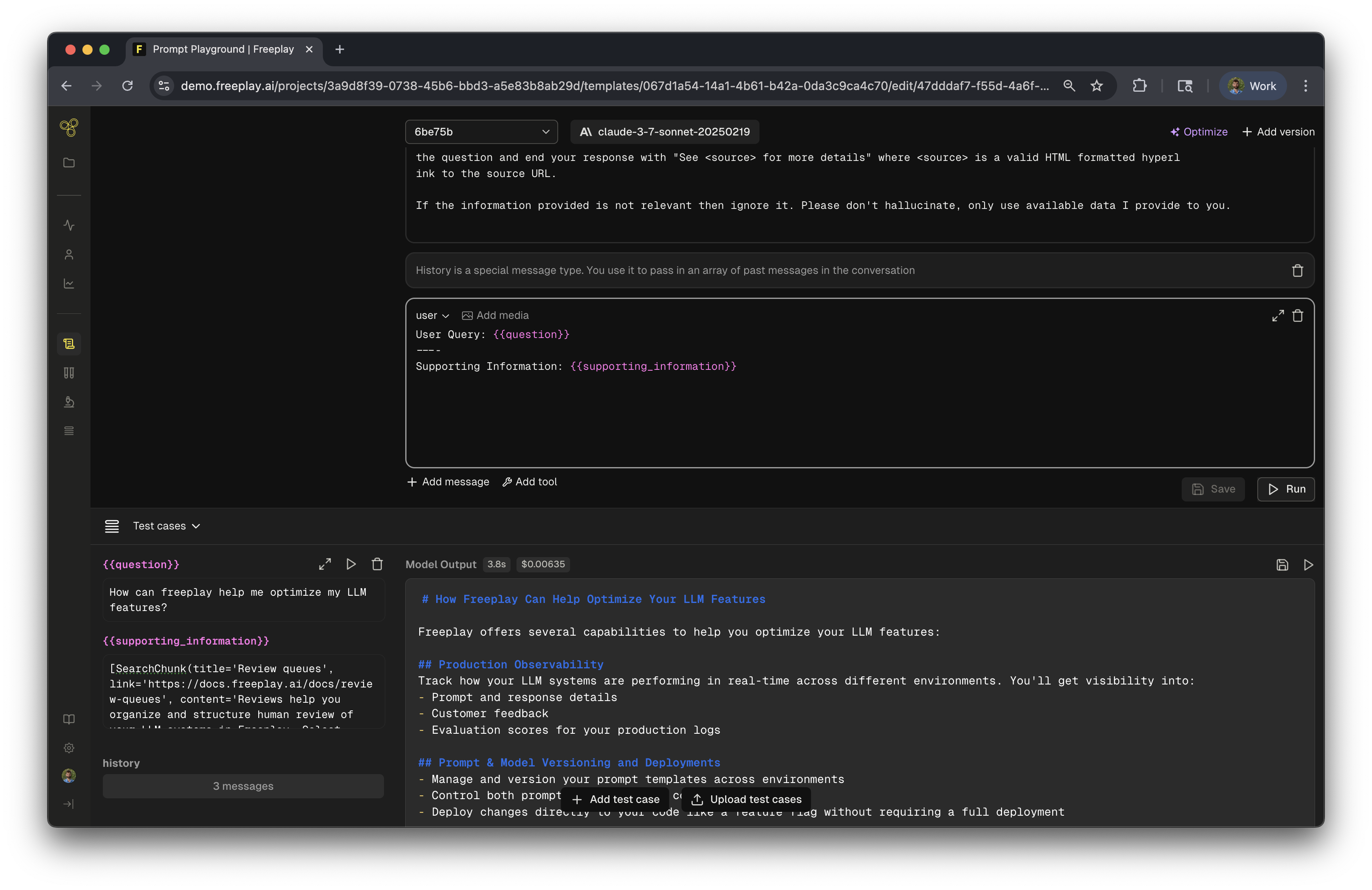
Test and Compare
The prompt editor is a fully interactive playground. Test different variations:
- Try different wording
- Adjust model parameters
- Compare providers side-by-side
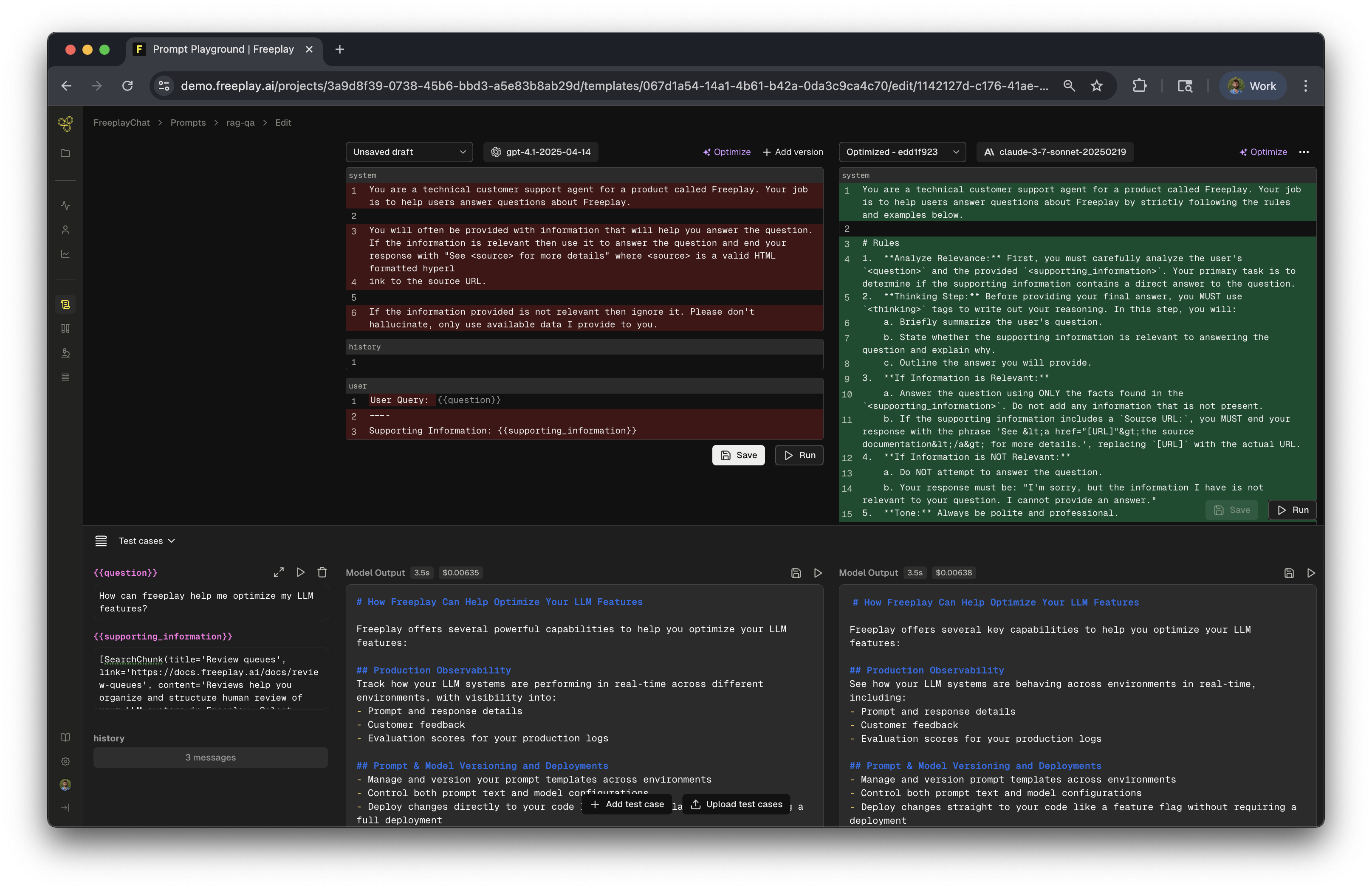
Example: Comparing OpenAI vs Anthropic responses with real data:
Save and Deploy
Once satisfied with your template:
- Save with a descriptive version name and notes
- Deploy to your chosen environments (dev, staging, production)
Step 2: Set Up Evaluations
Evaluations help you maintain quality as your application scales. While optional initially, we recommend setting these up to get maximum value from Freeplay.
Understanding Evaluation Criteria
For our RAG application, we can create evaluations that target each component:
- Context Relevance - Is the retrieved information relevant?
- Answer Faithfulness - Does the answer stick to the provided context?
- Answer Relevance - Does the answer address the question?
- Answer Correctness - Is the answer factually accurate?
This breakdown helps identify which parts of your pipeline need improvement.
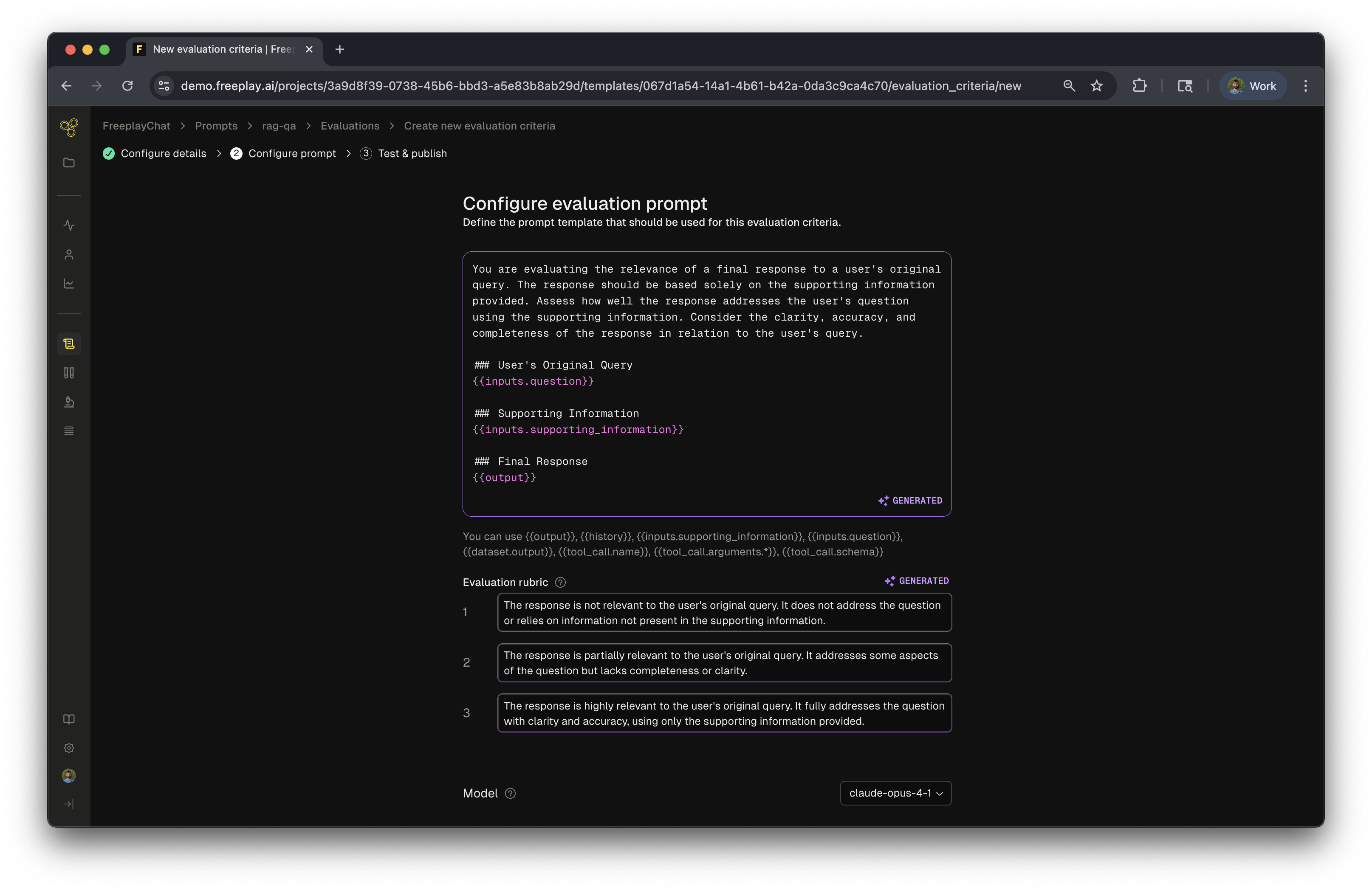
Learn More: Get a detailed guide on creating Evaluation Criteria
Updated about 24 hours ago