Agents in Freeplay
How We Use The Word Agent
The term “Agent” is widely used and can mean different things. For our purposes here, we mean any process in your application that makes use of multiple LLM calls to generate a single response. These may include tool usage or self-directed reasoning processes, but they don’t have to. Everything below applies to both “workflows” and “agents” as defined in Anthropic’s helpful guide to “Building Effective Agents.”Overview
Many LLM applications now go beyond simple completions to include multi-step workflows where an LLM makes decisions, uses tools, and follows complex reasoning processes to accomplish a task. These agent-based systems require specialized tooling to effectively monitor, test, and improve. Freeplay provides robust support to build and improve AI agents — allowing you to observe, evaluate, test changes, and iterate on agent performance, no matter how you manage orchestration. To get started, you’ll need to:- Configure prompt management in Freeplay, so that any prompts included in your agent can be tracked and versioned
- Record traces to Freeplay any time your agent runs (including any tool calls, additional metadata, customer feedback, and any evals you calculate in your code)
Key Benefits
- Agent Observability: Monitor and observe each of the steps, decisions, and outputs in your agent workflows to identify areas for improvement
- Automated Testing & Structured Experimentation: Test agent components individually or as complete workflows — with support to manage evals and testing datasets at both the individual component and full agent level
- Advanced Evaluations: Apply evaluations to any individual agent steps and/or overall agent performance
- Collaborative Debugging & Iteration: Easily share agent performance data and logs in ways that are easy to interpret for your whole team, in support of collaborative problem-solving
- Performance Insights: Quantify your agent’s performance on metrics you define, and report out findings to your wider organization
How Agents Work In Freeplay
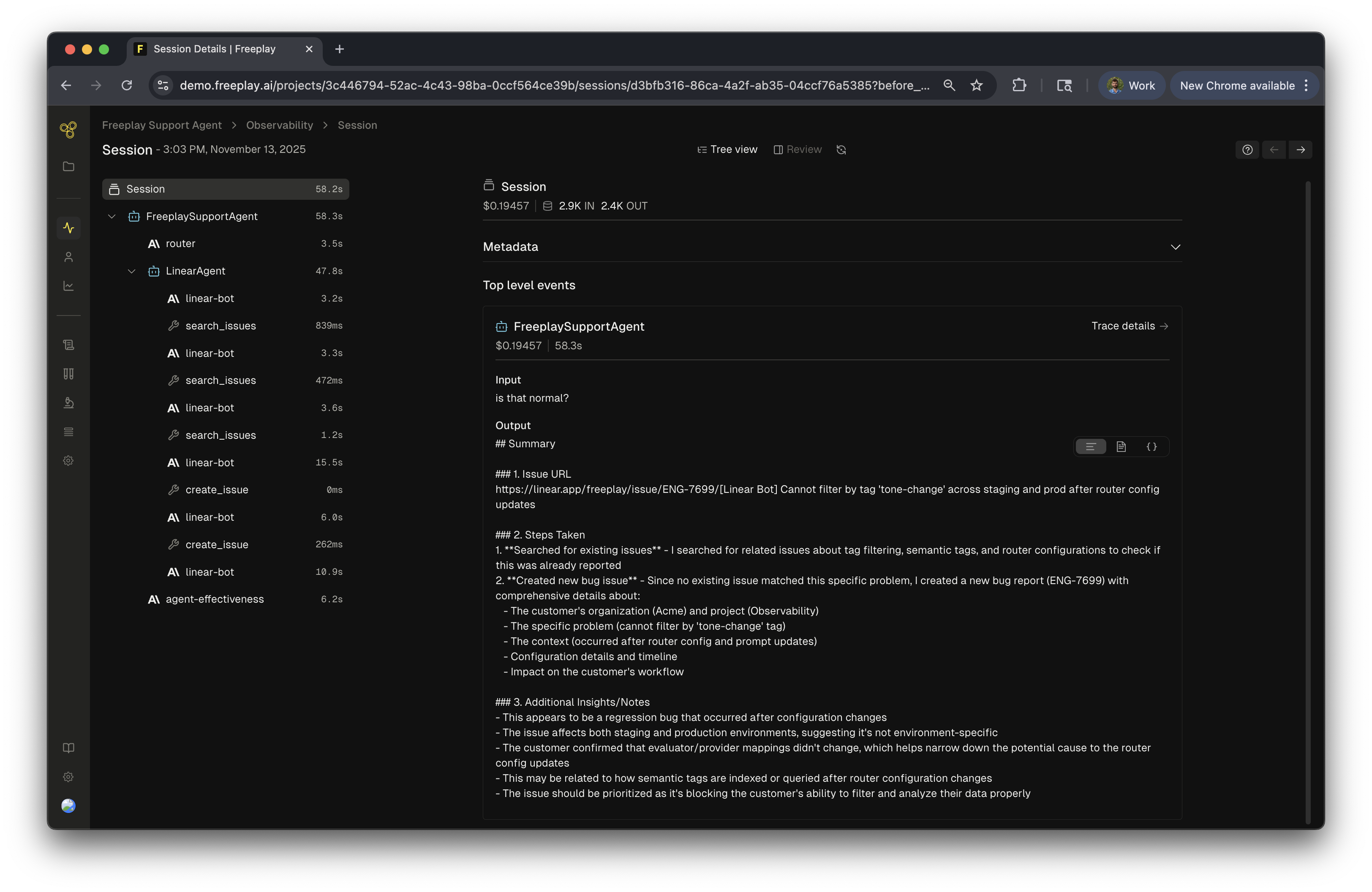
Freeplay depends on the concept of traces to support agent workflows. A Freeplay trace represents a logical grouping of LLM completions, tool calls, etc. that form a single agent task or workflow. Each trace can contain multiple completions, tool calls/results, and additional metadata about the agent — along with evaluation results and user feedback.Relationship between Sessions, Traces, and Completions
Understanding the hierarchy of data organization in Freeplay is essential for effectively tracking agent workflows. In short:- Completions: Individual LLM calls made up of a prompt and a response or output from a model.
- Traces: Optionally used to group related completions and tool calls, e.g. when multiple completions are used to generate a single chat turn or an agent flow.
- Sessions: The container for all completions and traces that make up a single customer interaction or single agent run.
- Note: These can be 1:1 with completions for a simple feature that just uses one prompt, or they can be very large at times, e.g. an entire conversation thread between a single user and a chatbot over multiple hours where each turn invokes an agentic workflow.
- One session per user interaction or single run of your agent (unless you’re building a multi-turn chatbot)
- One or more traces per agent or multi-step workflow
- Multiple completions within each trace
Logging Data to Agents
When logging agent activity, include not just the inputs and outputs, but also metadata about the agent version, capabilities, and any tool calls made during the process. The following dives into the details of how to log this data to Freeplay:Agent Creation
To track your agents with Freeplay, you’ll create traces and record agent interactions. When creating a trace for an agent, you can include:agent_name(string): The name of the agent being used, which gets used elsewhere in Freeplay for evals, dataset compatibility, etc.custom_metadata(key-value pairs): Additional metadata you choose to record about the agent
Recording Intermediate Completions & Tool calls within an Agent
For each step in your agent’s workflow, you’ll want to record the LLM completions and any tool calls made. To record this information to a trace, pass thetrace_info to the RecordPayload function along with any completion or tool call/results and they will be tied to the trace.
Two approaches to logging tool calls
Freeplay supports two approaches for recording tool calls:| Approach | Best for | How it works |
|---|---|---|
| Default (in completions) | Simpler integrations, standard tool-calling patterns | Tool calls are recorded as part of the message history. The tool call appears in the LLM’s output message, and the tool result appears as an input message to the next LLM call. When you call formatted_prompt.all_messages(), tool calls and results are concatenated into the history object alongside other messages. |
| Explicit tool spans | Complex agent debugging, tool execution timing, separate tool result visibility | Create separate traces with kind='tool' for each tool execution. This renders tool arguments and results as independent spans in the trace view, in addition to their presence in the message history. |
Recording LLM Outputs and Client-Side Evaluations
When recording agent outputs, you can also include any evaluation results calculated in your code (details here):eval_results(dict): Dictionary of evaluation metrics for the trace (can include numeric, string, or boolean values)
Updating Agents with Customer Feedback
You can add customer or system feedback to traces, which will be treated as a special class of metadata in Freeplay.Agent Evals
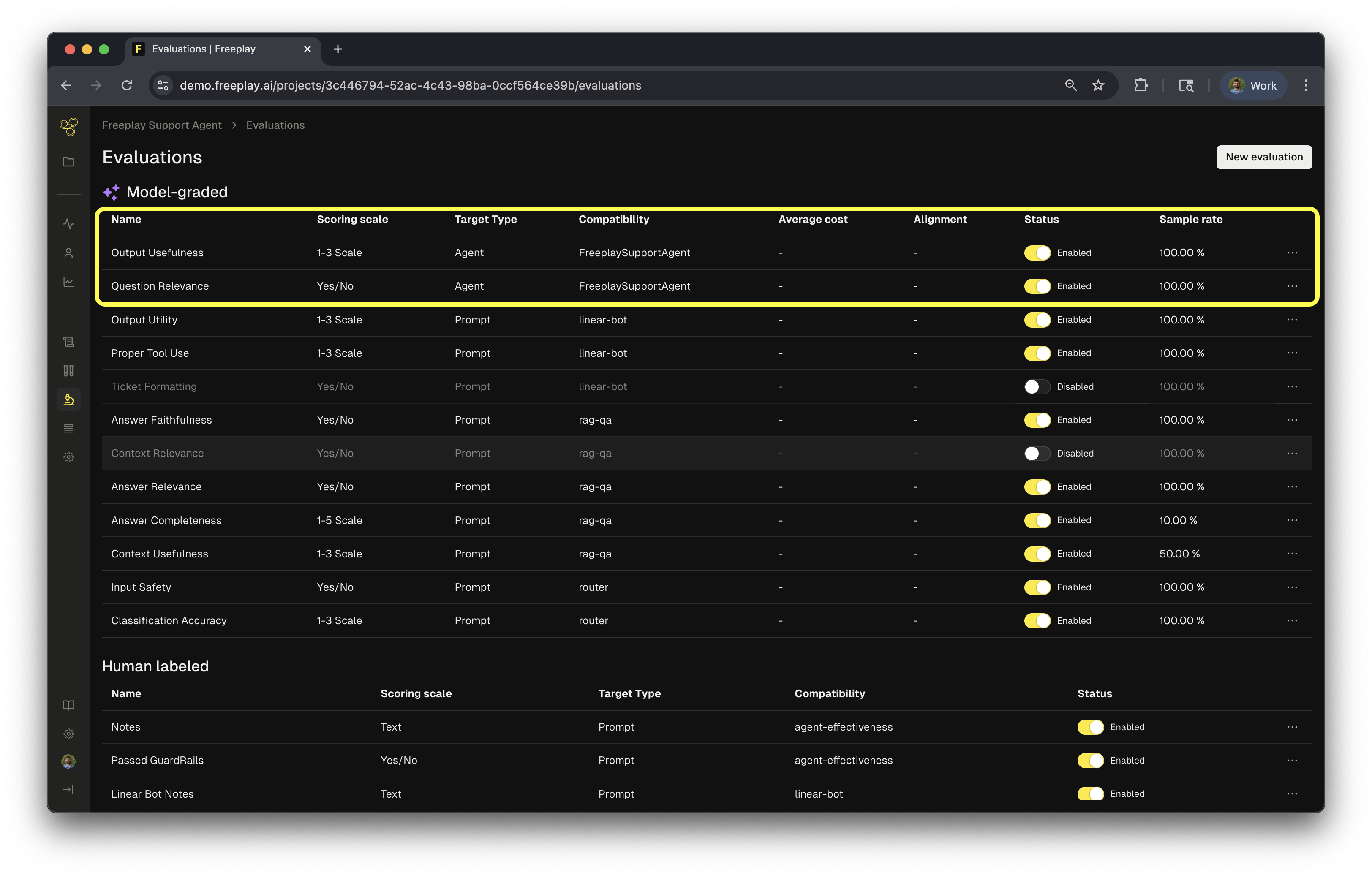
What Agent Evals Do
Agent Evals continuously assess your agent’s outputs using both AI models and human reviewers. Think of them as quality checks that run alongside your production system, alerting you when performance drifts from your standards. You can evaluate various aspects like response usefulness, clarity, accuracy, and whether the agent is actually solving the problem it was given.Setting Up Your Agent Eval
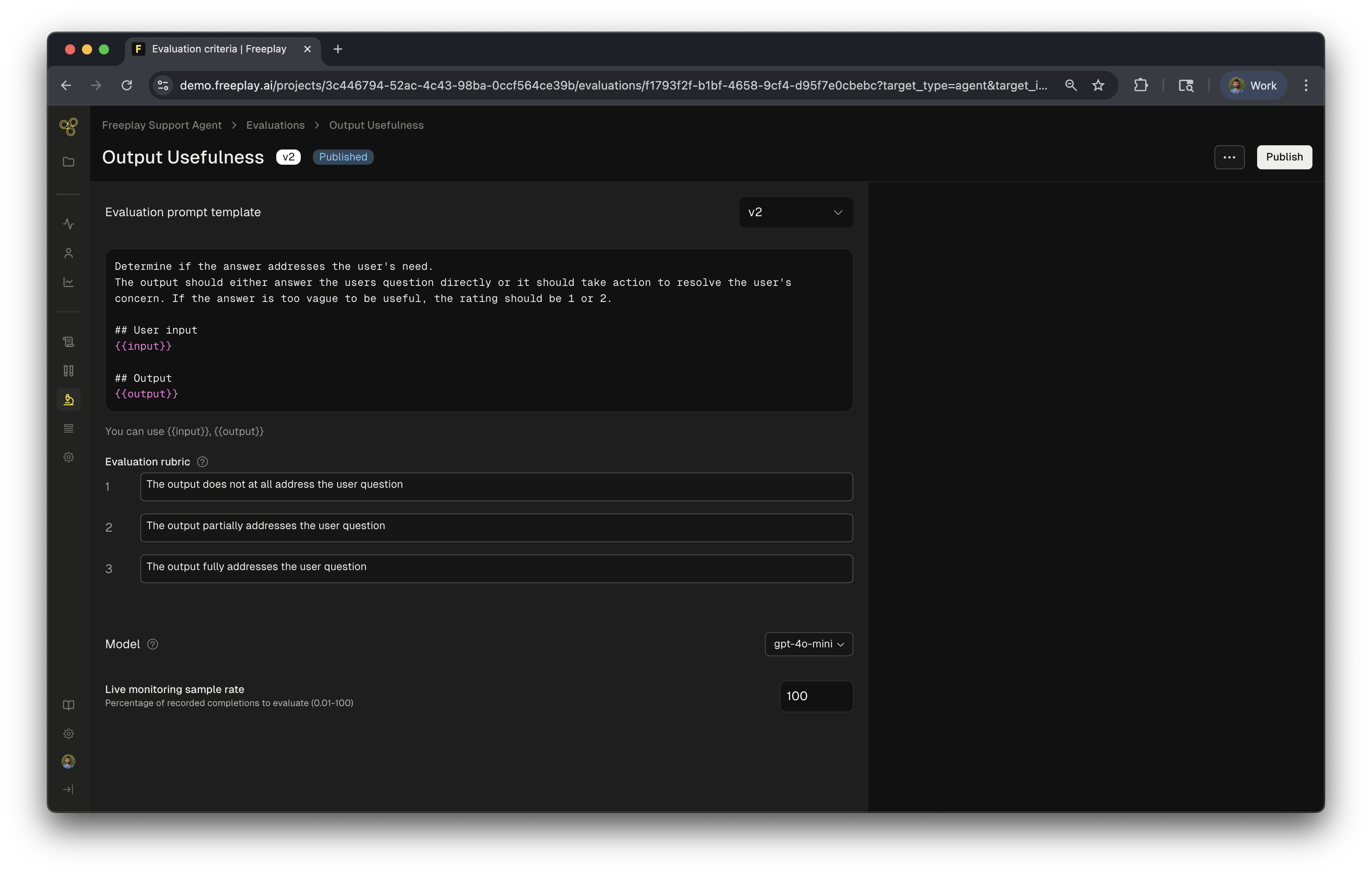
- Define your goal - What aspect of performance matters most? (e.g., “Is the response helpful?” or “Did the agent extract the correct information?”)
- Set clear criteria - Describe what success looks like for this evaluation
- Configure monitoring - Choose your evaluation model and set how often to sample live production data
- Deploy and track - Save your eval and start monitoring your agent’s real-world performance
Agent Datasets & Testing
Datasets
Agent datasets enable end-to-end testing of your agent workflows, allowing you to assess the complete behavior of your system under real or representative conditions. These datasets serve as a foundation for understanding how changes—such as prompt revisions, tool updates, or orchestration logic adjustments—affect the overall output of your agent. In Freeplay, agent datasets are powered by trace-level logging. By assigning an Agent Name to your traces, you create a logical grouping of all related agent runs. This grouping allows you to filter and review traces in the observability dashboard and assemble them into datasets for future testing and evaluation. You can create an agent dataset in two ways:- From the observability dashboard by selecting traces with the same Agent Name.
- Directly from the trace view by saving specific traces to a dataset.
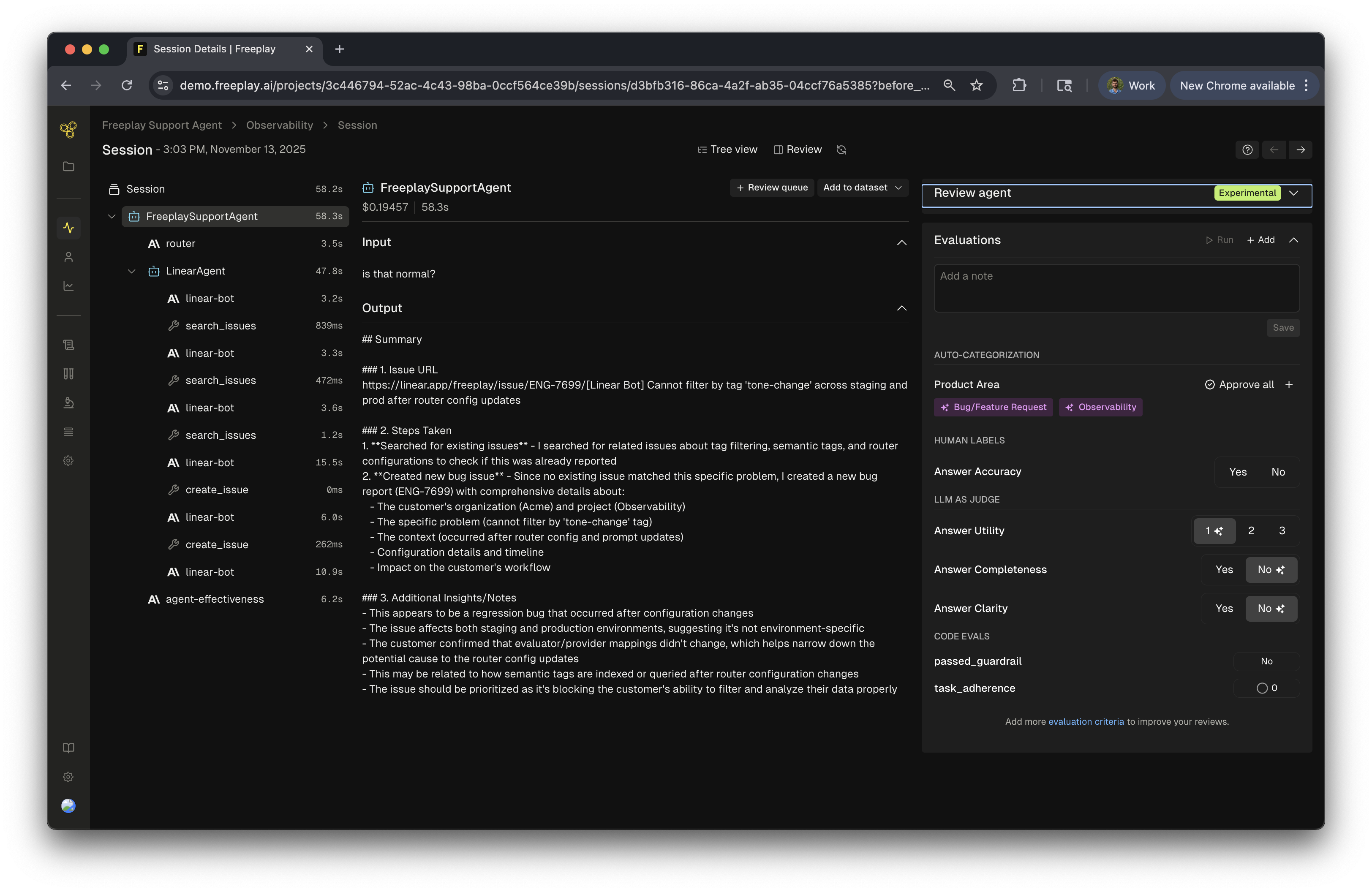
Testing
Once you’ve assembled an agent dataset, you can use it to run structured tests against your agent. These tests provide visibility into system performance, surfacing both top-level metrics and step-level details that inform iteration and deployment decisions. Running tests on agent datasets allows you to apply evaluations at both the trace and prompt level and understand how changes impact overall system behavior. The example below illustrates a completed test run in Freeplay. High-level agent evaluations are shown at the top, while granular prompt-level evaluations are displayed below. This layered view enables you to assess both the success of the full agent and the contributions of each step. To execute these tests programmatically, you can use the Freeplay SDK in the same way you would initiate a standard test run. See the SDK documentation for full implementation details.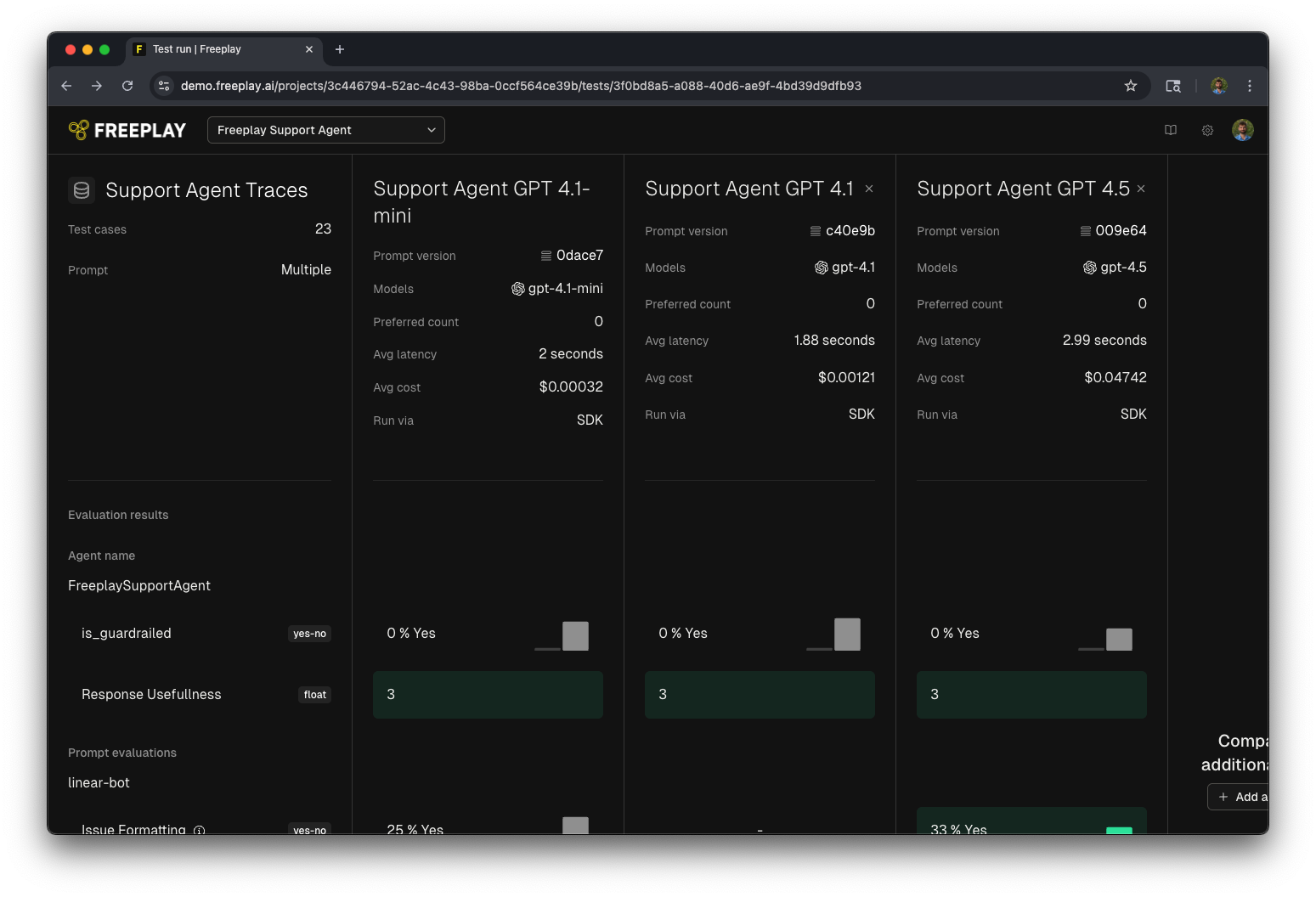
FAQ
How do I update traces in my current Freeplay implementation?
If you’re already using Freeplay, you’ll need to:- Update to the latest SDK version
- Modify your trace creation code to include
agent_nameandcustom_metadata - Update your recording logic to include evaluations and/or customer feedback as needed
Do I need to use traces to work with agents?
While not strictly required, using theagent_name value with traces provides significant benefits for building agents:
- Better visibility into multi-step processes
- Ability to evaluate agents from end to end
- Ability to run and organize tests at the agent level, separate from individual components
- More granular performance metrics
- Enhanced debugging capabilities
How does a trace map to an agent?
The relationship between traces and agents is flexible and ultimately up to you:- One trace can represent one complete agent task
- Multiple traces can represent different aspects of a complex agent
Best Practices
- Naming Convention: Use consistent agent naming to make searching and analysis easier
- Metadata Strategy: Define a minimum standard set of metadata fields for your agents up front. (You can always add more later too.)
- Granular Evaluations: Create evaluations that target specific agent components and end-to-end behaviors
- Representative Datasets: Build datasets that cover the range of expected agent tasks
- Regular Testing: Build batch testing with evals into your agent development workflow to catch issues and regressions early
Next Steps
Ready to get started with agents in Freeplay?- Update your Freeplay SDK to the latest version
- Review our code examples for implementing agent trace logging
- Create your first agent dataset and evaluations (where the dataset consists of inputs and outputs for the entire end-to-end agent behavior)
- Set up dashboards to monitor agent performance