What are datasets and why are they important?
Testing and evaluation are key aspects of the LLM development cycle. Your test quality and reliability are a function of two primary components: your Evaluators and your Datasets. In this guide, we are going to focus on Dataset curation. Simply put, datasets are collections of inputs and outputs that you can use to test your LLM systems. Each example’s output represents either a golden response (the ideal answer) or a captured failure case from production. Including outputs is strongly recommended — they are what evaluations compare new LLM responses against during test runs. For more details, see Understanding the Output Field. Datasets are important because for your tests to be truly informative your datasets need to accurately represent the issues and situations your LLM systems face in the wild. We’ll cover how we at Freeplay think strategically about building datasets and then look tactically at how to curate datasets inside of Freeplay.Dataset Curation Strategy
Once your team has decided what product or feature you want to build, a common next step is curating your datasets. Many teams will build a single dataset of various scenarios for an LLM feature and instinctively stop there. While one dataset is a fantastic starting point, teams quickly realize that multiple datasets are crucial for effective testing and experimentation. Broadly speaking there are two types of datasets: Targeted datasets and Broad-based datasets.Targeted datasets
Targeted datasets are datasets that are focused on a narrowly defined issue or situation. For example, let’s say you’re working on an e-commerce use case in which we are using an LLM to answer customer questions about their orders. The pipeline has two components:- First, the LLM generates a SQL query from the user question
- Then, the LLM uses the results of that query to generate an answer
Broad-based datasets
Broad-based datasets are datasets that include a wide array of examples and are not focused on any specific issue or situation. The classic example of a broad-based dataset would be the “golden set.” A golden set is a dataset consisting of examples hand-curated by humans to be the ideal output for some given input. Unlike a targeted dataset, broad-based datasets contain a variety of situations meant to capture the totality of cases your LLM system needs to be able to handle. This kind of dataset is often used for benchmarking or regression testing. These two types of datasets can then be used together during experimentation. Continuing our e-commerce example from earlier, let’s say you’re focused on reducing hallucinations in SQL query generation. You can first focus on making prompt and model changes for that specific issue, frequently testing against your targeted dataset along the way. Then once you think you have a fix in hand, you test the new config against your broad-based dataset to ensure you haven’t regressed on other dimensions.Anatomy of a Freeplay Dataset
Now that you’re familiar with the primary types of datasets, let’s take a look at what a Freeplay dataset consists of.- Name - ex. “Query Hallucinations”
- Description - ex. “Sessions where the model referenced an invalid table”
- Prompt Compatibility - A set of inputs that your dataset will be compatible with.
- Examples - Examples are combinations of inputs and outputs that you as the user save to a dataset. The output should be either a golden response or a captured failure case — see Understanding the Output Field for guidance.
Curating Datasets in Freeplay
Step 1: Create a new Dataset
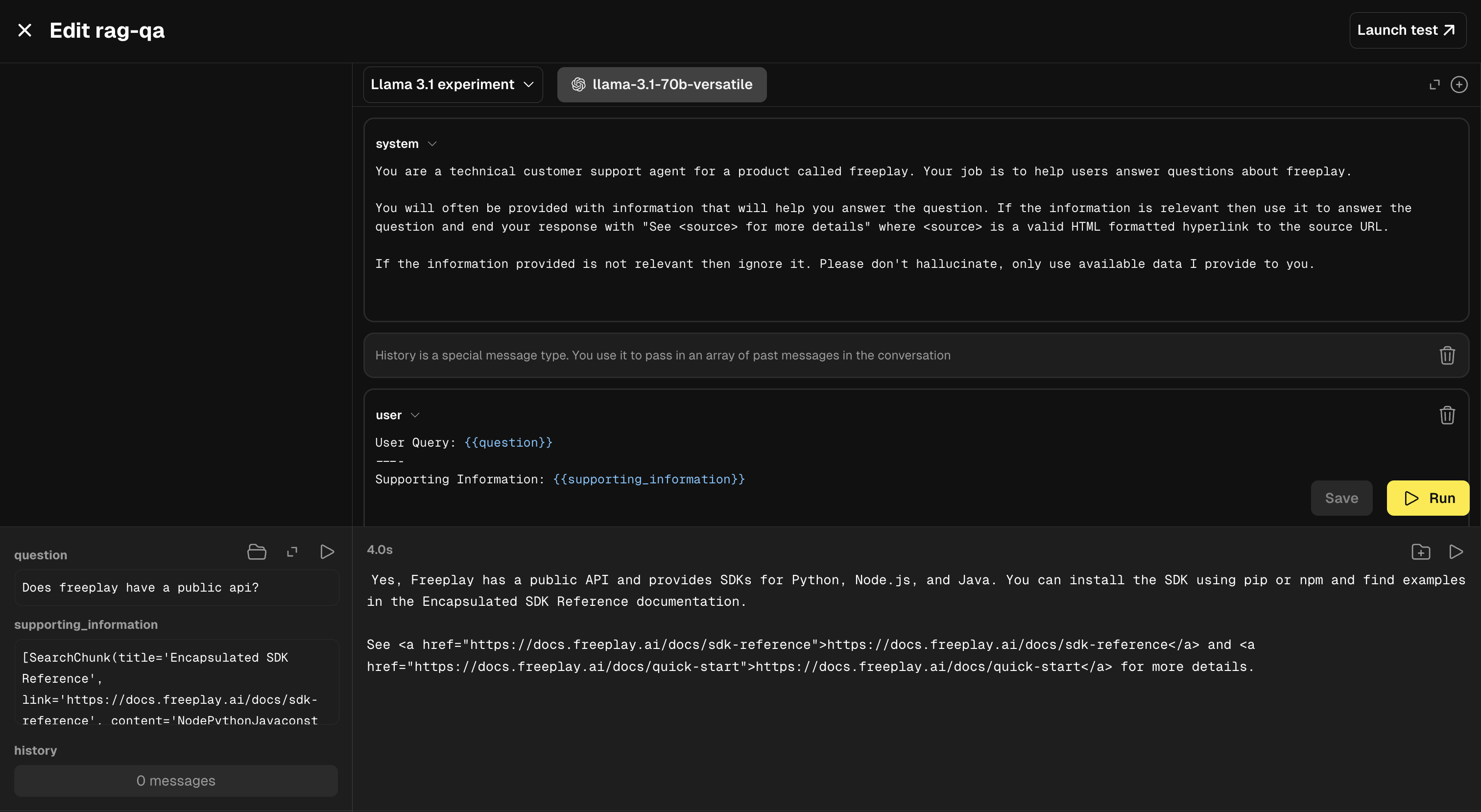
Navigate to the Datasets tab and select “Create dataset”. Give your dataset a Name and Description, then set your Prompt Compatibility. You’ll need to decide what prompt(s) you want your dataset to be compatible with. Compatibility is determined by the prompt’s input variables. Datasets can be compatible with multiple prompts as long as those prompts share at least one common input variable.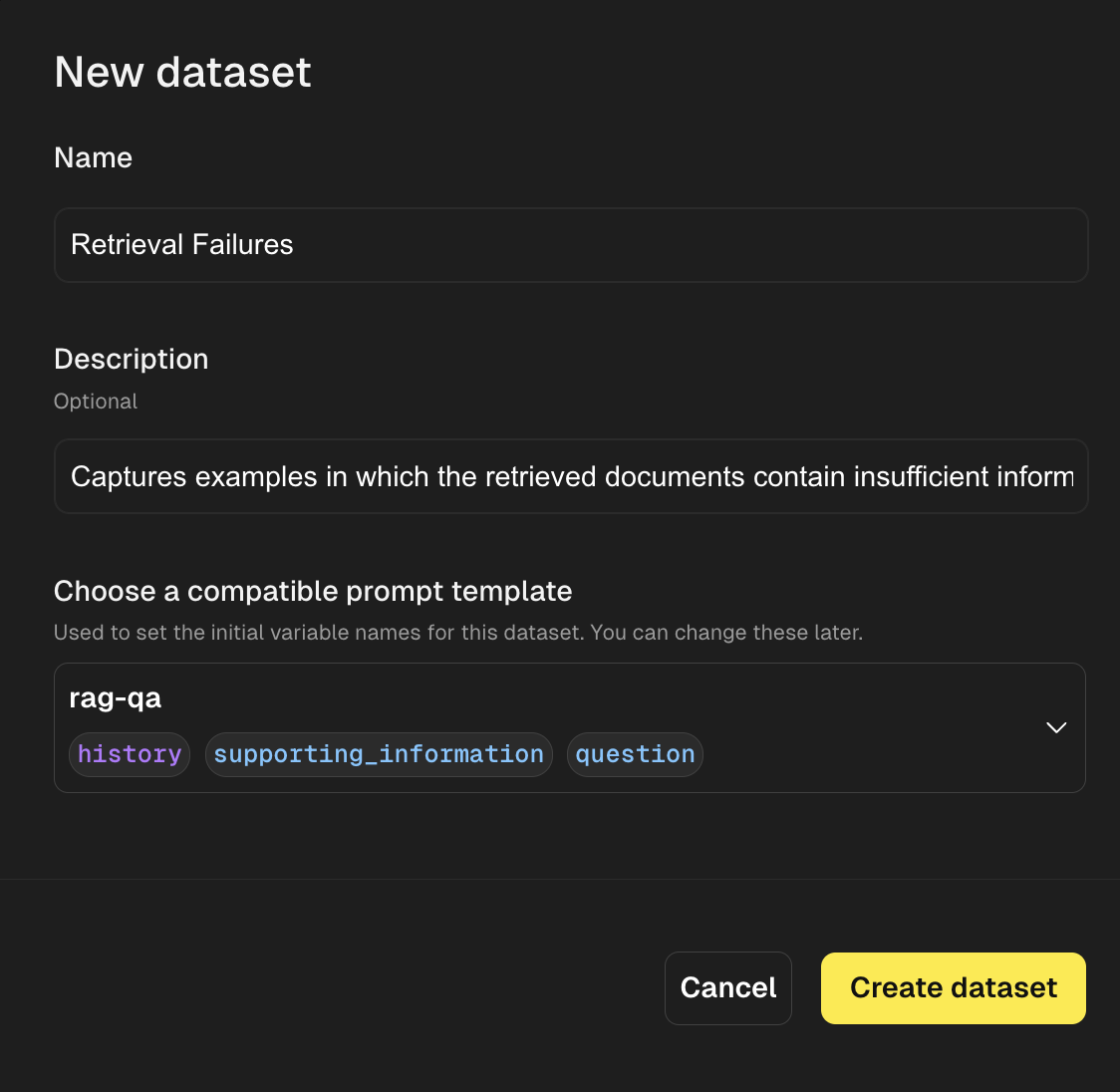
Step 2: Add Examples
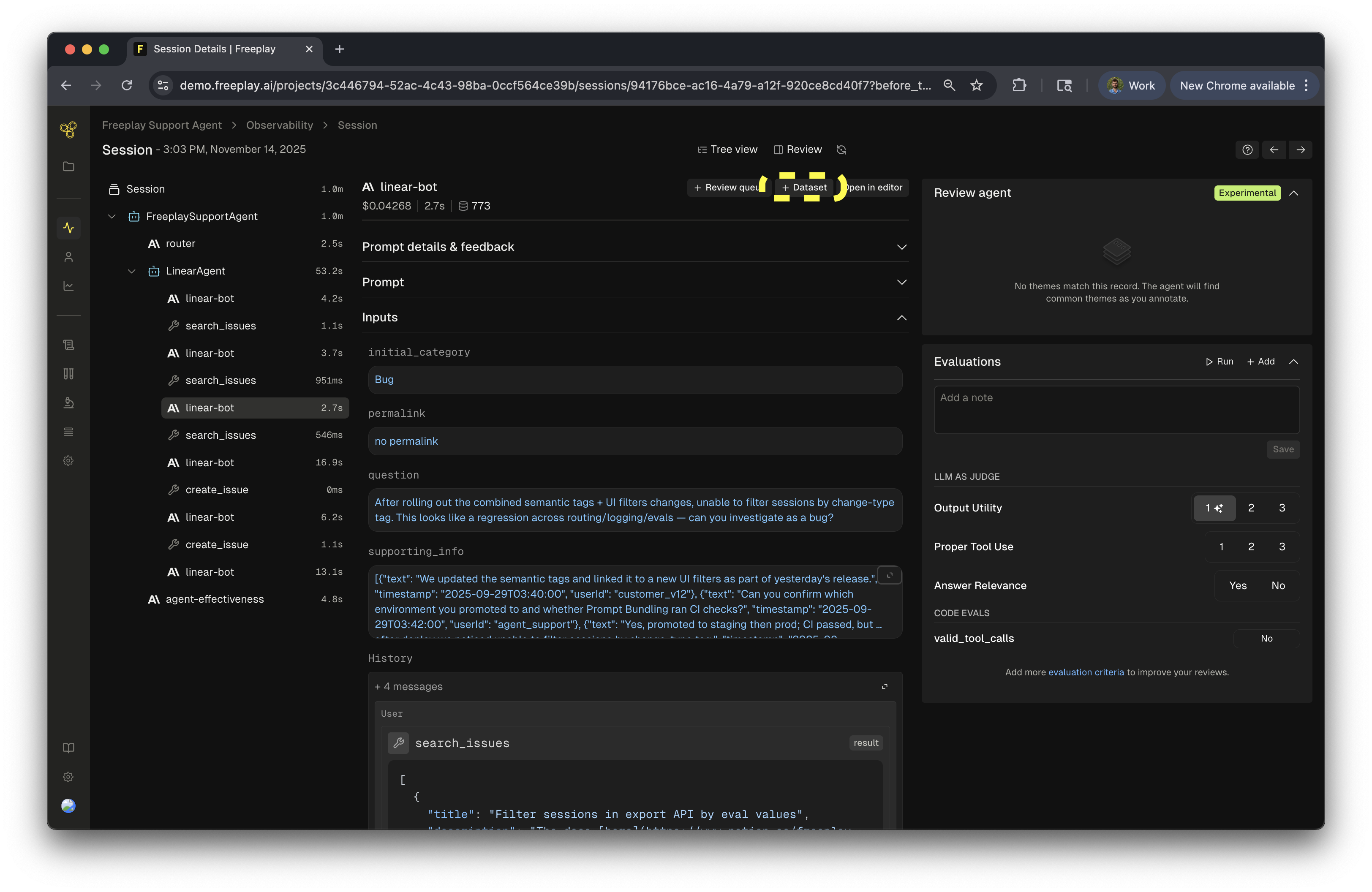
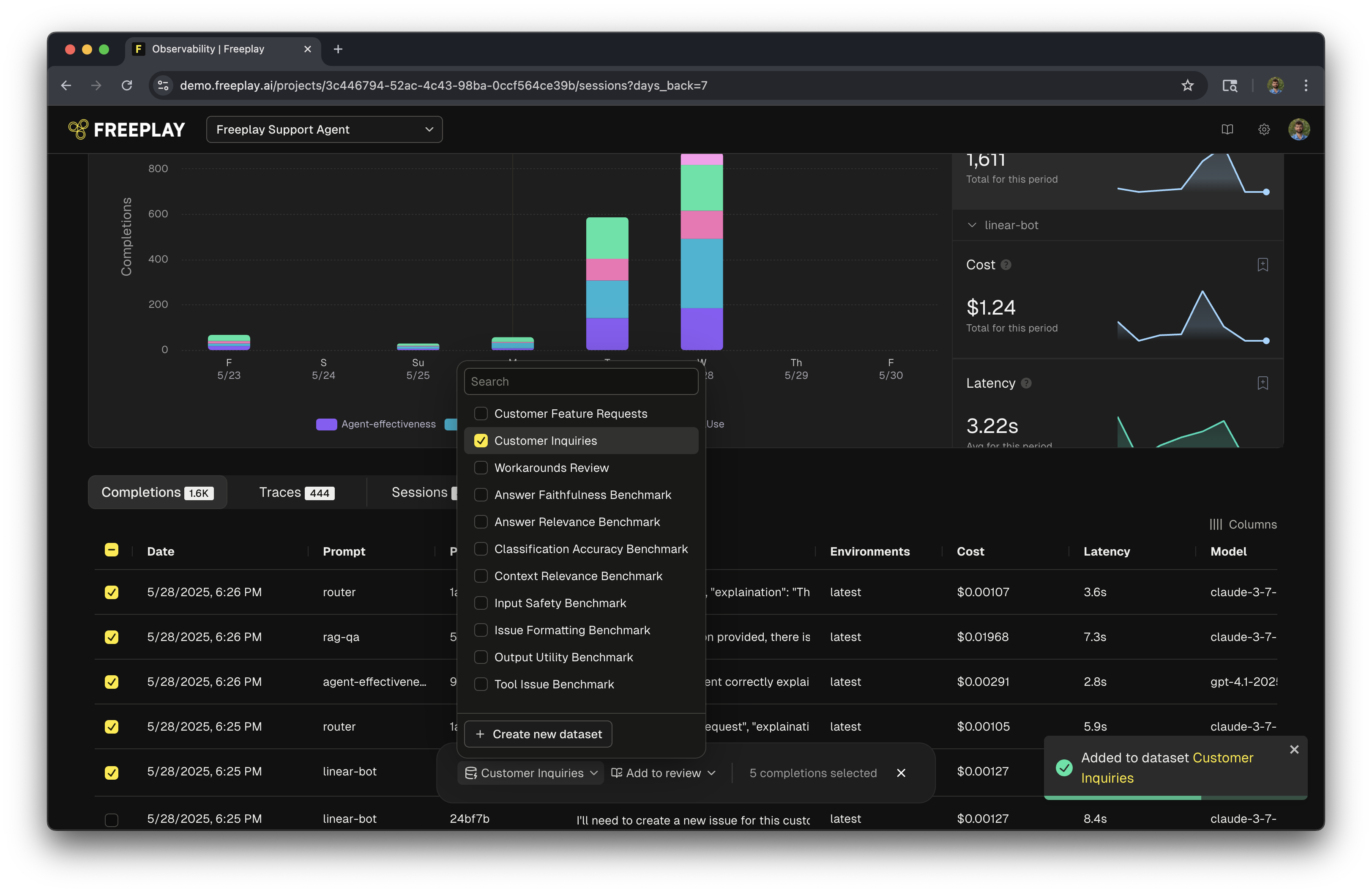
There are a number of ways to add examples to a dataset. Add from completion From any completion you can hit “Add to dataset” to create a new example from that completion. This is often a big part of the human review flow, as reviewers are labeling data they can actively be building datasets as well.Curating Samples from Production Data
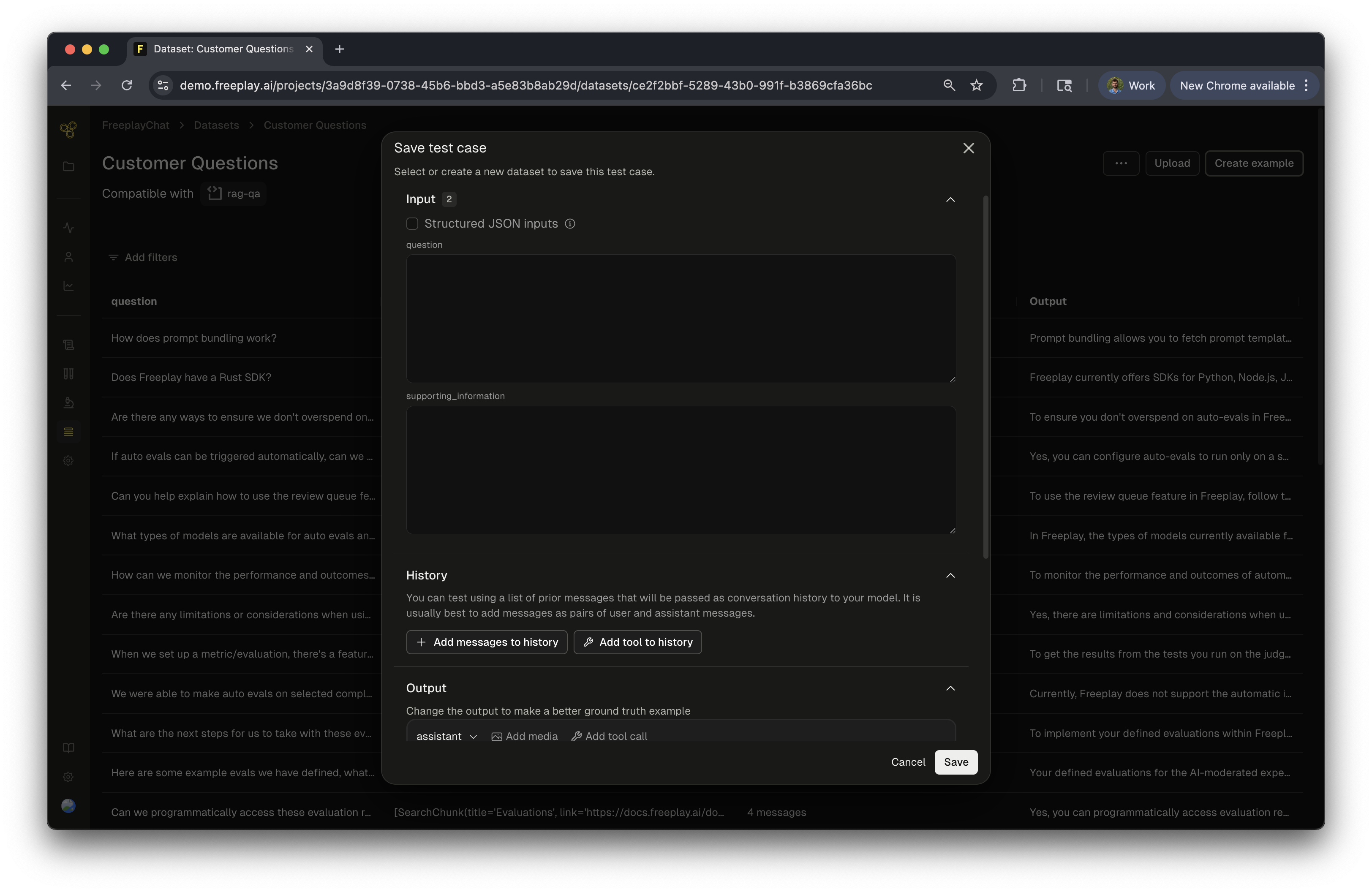
When adding new samples directly from Observability, you have the option to manually curate them to be representative samples in your dataset. When you open up the ”+ Dataset” modal, it will give you the ability to curate any of the inputs, variables, history and output by adding additional messages, tool calls, multimedia and more. This allows you to add quality samples to your dataset making it even more useful for testing different parts of the product such as failure modes, successful cases and more!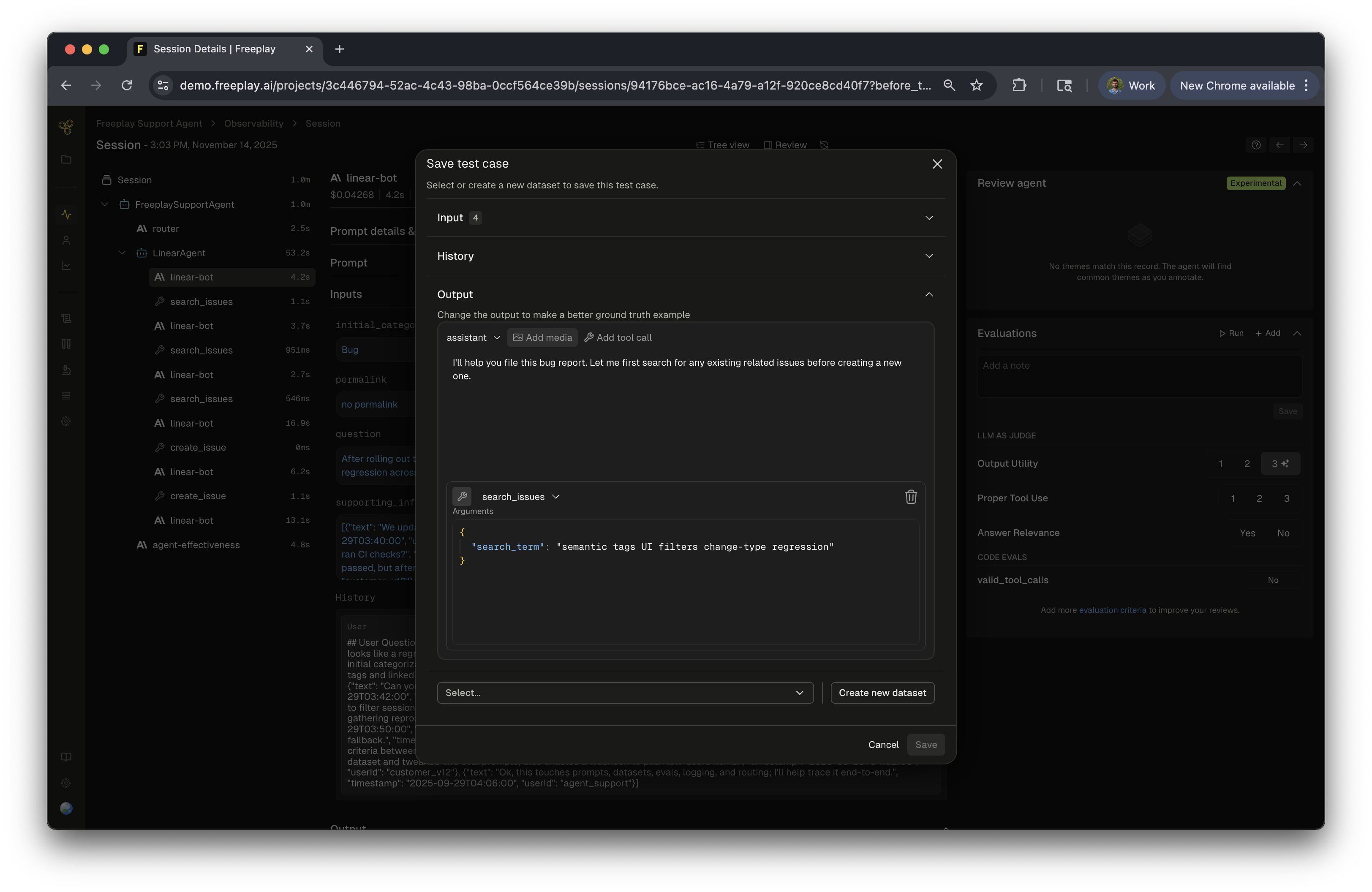
Step 3: Run a Test against your Dataset
After you’ve created a dataset you can run a batch test with any of your compatible prompts. Batch tests can be kicked off either from the Freeplay app or via the SDK. To run a batch test from the UI go to the Tests tab and click “Run Test”. From there you can configure the test by selecting the prompt version you want to test and the dataset you want to test with.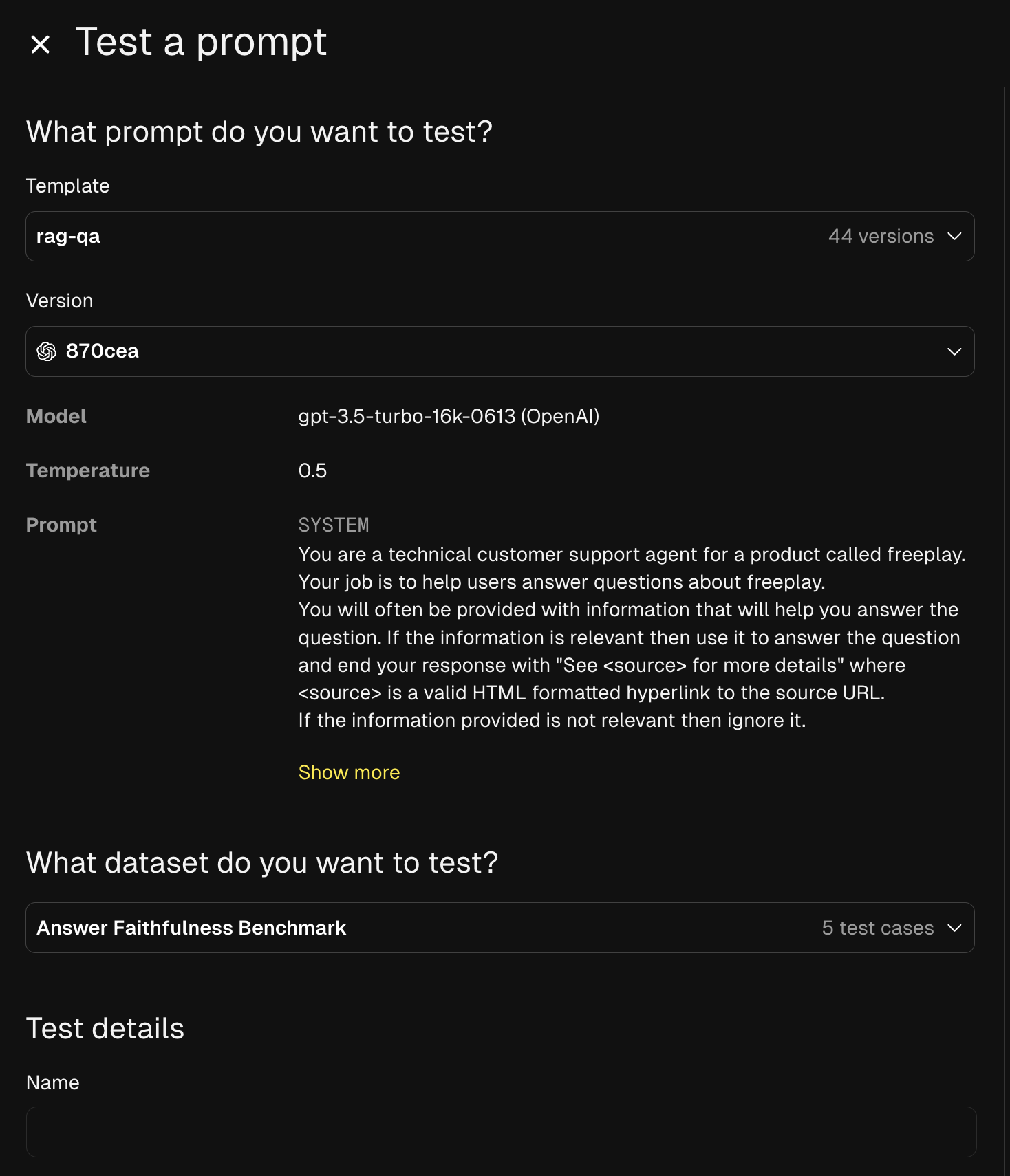
Step 4: Managing Datasets
You can manage your dataset on an ongoing basis in the Datasets tab. Here you can add, edit, and delete examplesBonus: Use your Dataset in the Playground
When editing a prompt in the playground you can pull in examples from your dataset and run them in real time to test your changes. In the prompt editor click the folder icon and load in examples