Code Evaluations in Freeplay
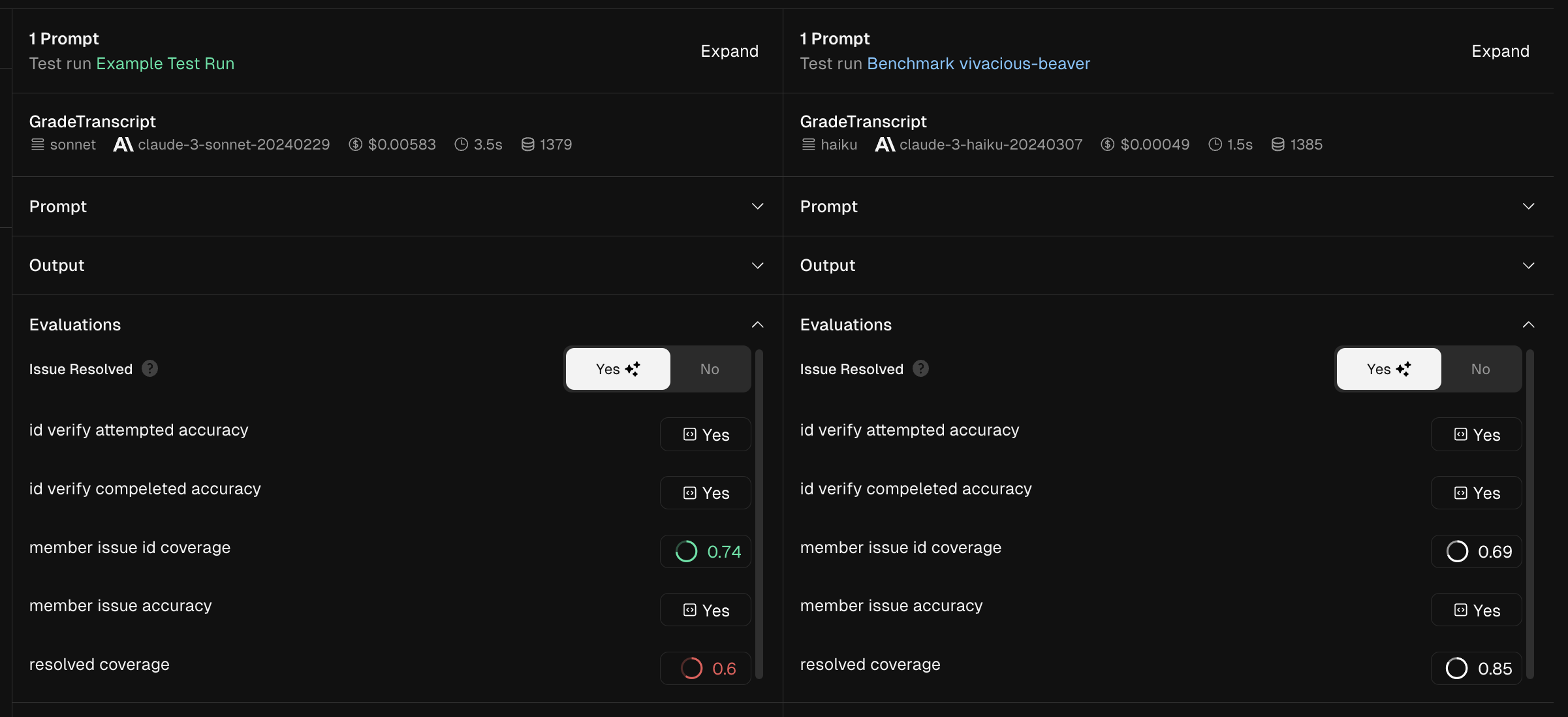
- Individual Sessions
- Test Runs executed with our SDK or API, which can include comparisons to ground truth data
What’s Next Now review each evaluation type and then move onto test runs once all your evaluations are configured!