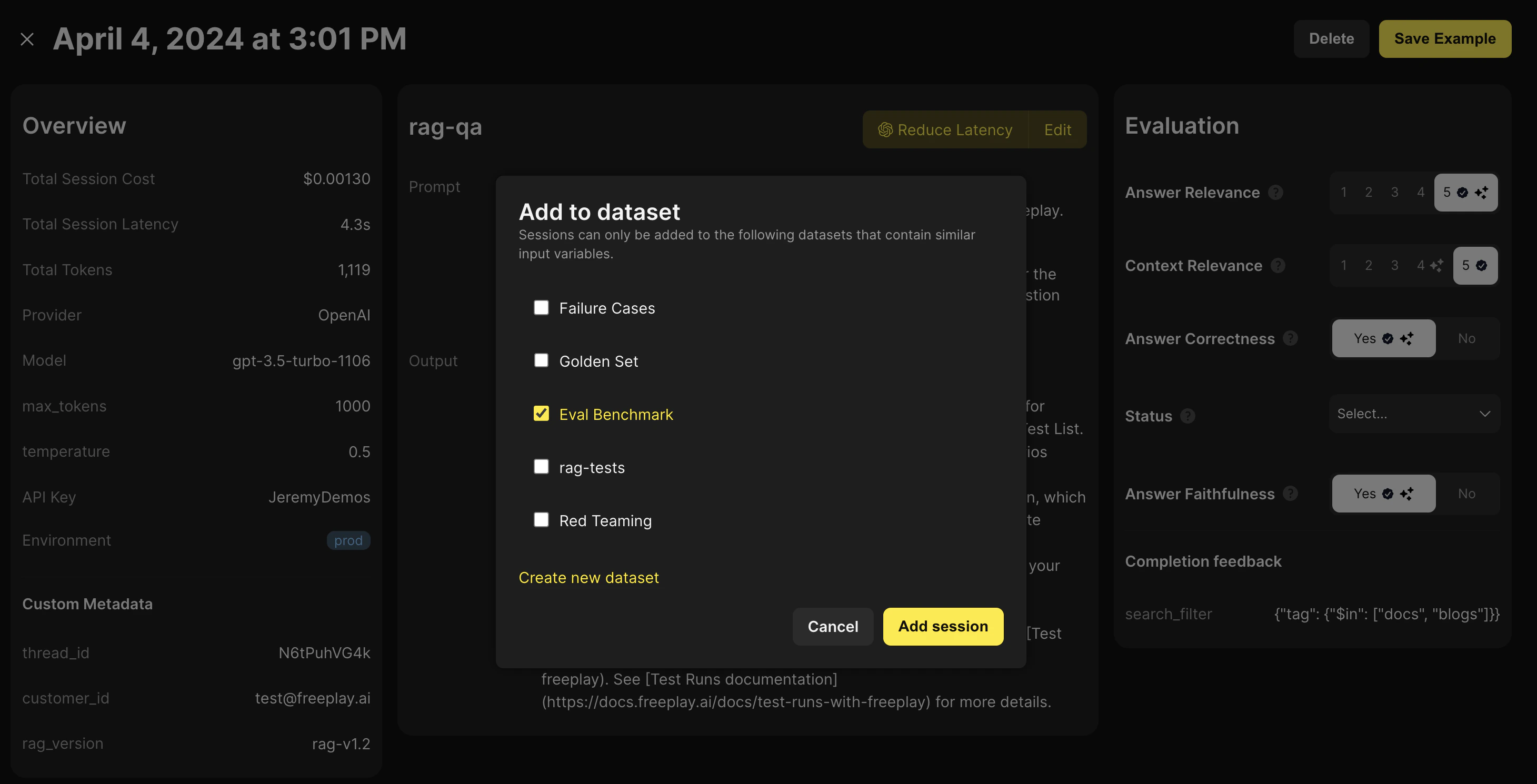
# start timer for logging latency of the full chain
start = time.time()
# run semantic search
search_res, filter = vector_search(message, top_k=top_k,
cosine_threshold=cosine_threshold,
tag=tag, title=title)
# get the formatted prompt
prompt_vars = {
"question": message,
"supporting_information": str(search_res)
}
# get a formatted prompt for your primary provider
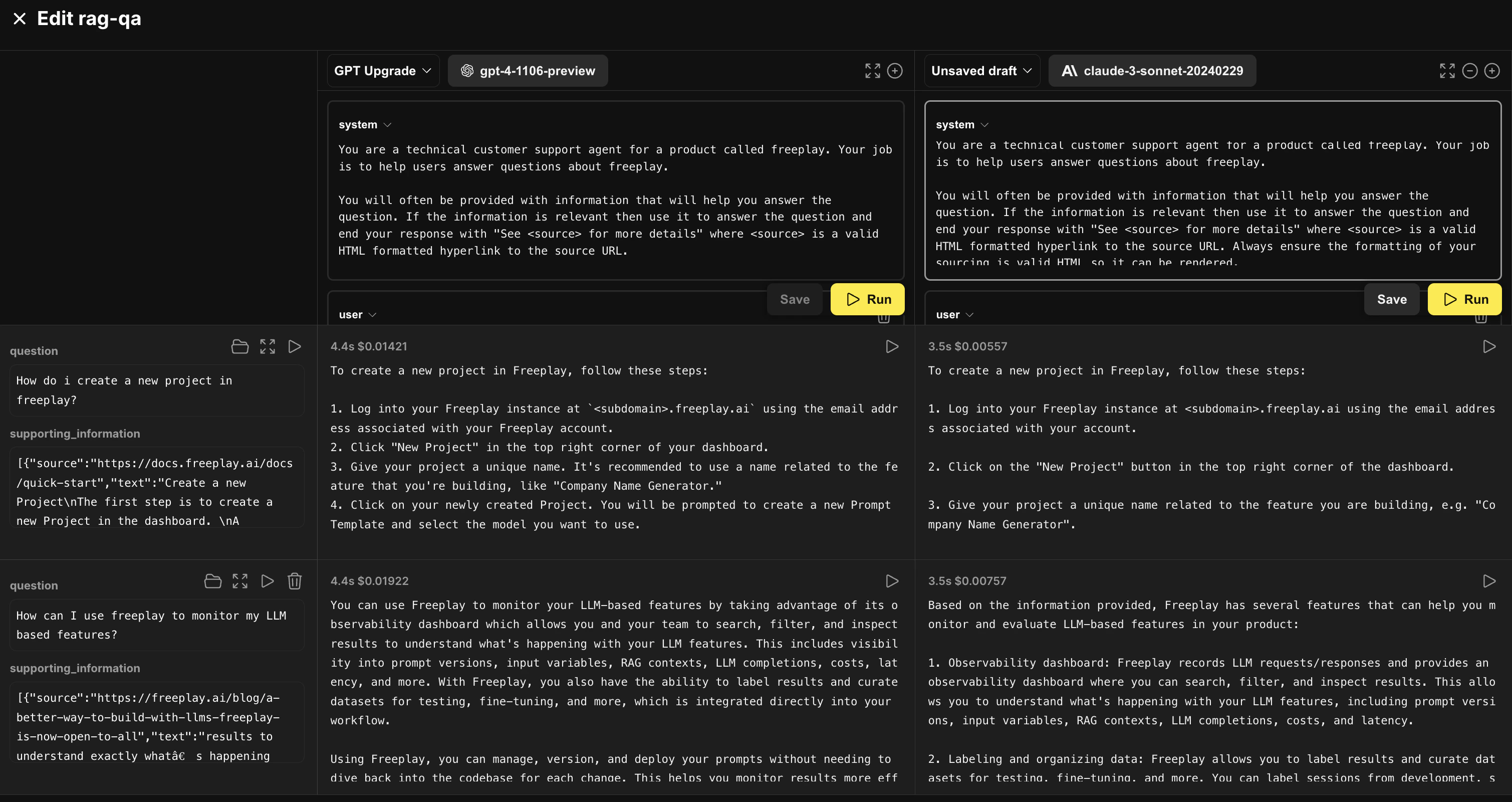
formatted_prompt = fpClient.prompts.get_formatted(
project_id=freeplay_project_id,
template_name="rag-qa",
environment="prod",
variables=prompt_vars
)
# first try making a request with your primary
try:
chat_completion = openai.chat.completions.create(
model=formatted_prompt.prompt_info.model,
messages = formatted_prompt.messages,
**formatted_prompt.prompt_info.model_parameters
)
content = chat_completion.choices[0].message.content # update messages
messages = formatted_prompt.all_messages(
{'role': chat_completion.choices[0].message.role,
'content': content}
)
except: # fetch the prompt for our fallback provider
formatted_prompt = fpClient.prompts.get_formatted(
project_id=freeplay_project_id,
template_name="rag-qa",
environment="fallback",
variables=prompt_vars
)
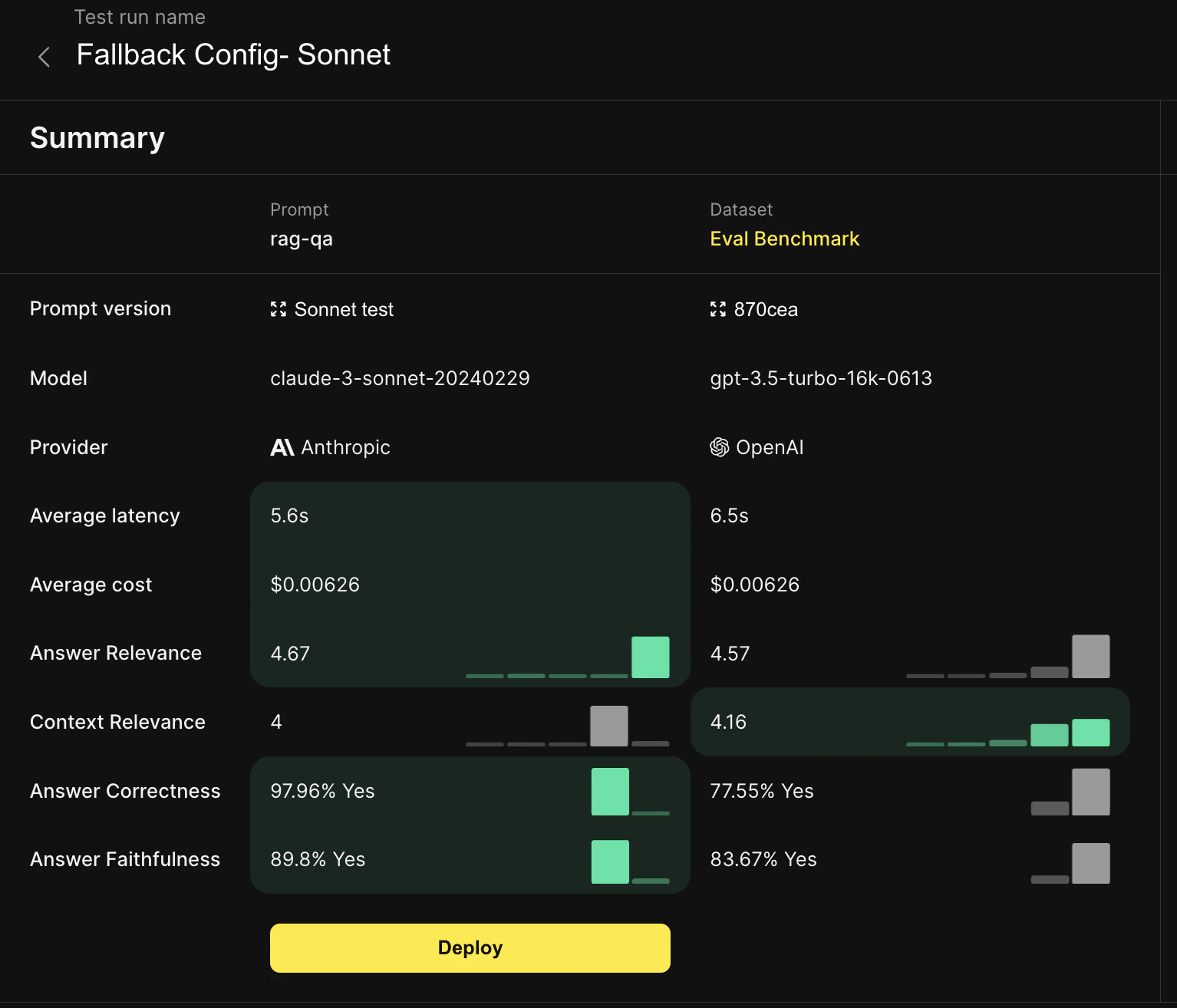
chat_completion = anthropicClient.messages.create(
model=formatted_prompt.prompt_info.model,
system=formatted_prompt.system_content,
messages=formatted_prompt.llm_prompt,
**formatted_prompt.prompt_info.model_parameters
)
content = chat_completion.content[0].text
messages = formatted_prompt.all_messages(
{'role': chat_completion.role,
'content': content}
)
# log latency
end = time.time()
# create an async record call payload
record_payload = RecordPayload(
project_id
all_messages=messages,
inputs=prompt_vars,
session_info=session,
prompt_version_info=formatted_prompt.prompt_info,
call_info=CallInfo.from_prompt_info(formatted_prompt.prompt_info, start_time=start, end_time=end)
)
# record the call
completion_log = fpClient.recordings.create(record_payload)