
Test Runs
Test Runs Overview
Test Runs provide structured testing for your AI systems, enabling you to validate performance across datasets and catch regressions before they reach production. Freeplay supports two complementary testing approaches designed for different stages of your development workflow.
Testing Approaches
End-to-End Test Runs
End-to-end testing validates your complete system workflow including agents, RAG pipelines, and multi-step processes. When you change any component—whether it's a prompt, tool, or orchestration logic—you need to understand how it affects your final output. These tests execute through the SDK, giving you full control over your system's execution path.
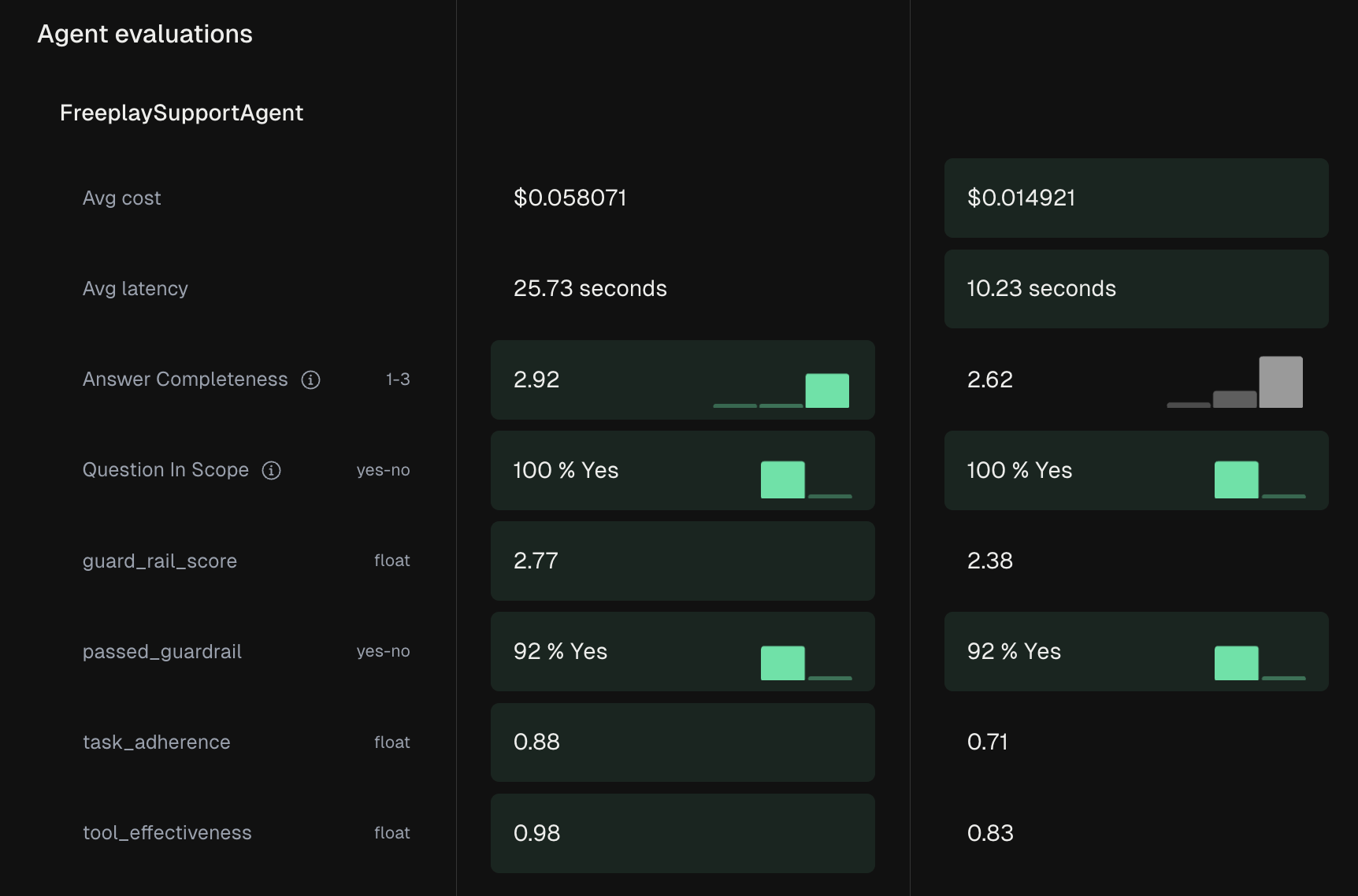
End-to-end tests are essential for production validation, agent systems with multiple prompts and tools, RAG pipelines, and multi-turn conversations. They capture the full complexity of your system as users experience it.
Learn more about End-to-End Testing →Component-Level Test Runs
Component testing focuses on individual prompts and model changes in isolation. This approach enables rapid iteration during prompt engineering without the overhead of running your entire system. You can execute component tests through either the Freeplay UI for quick, no-code testing, or the SDK for programmatic control.
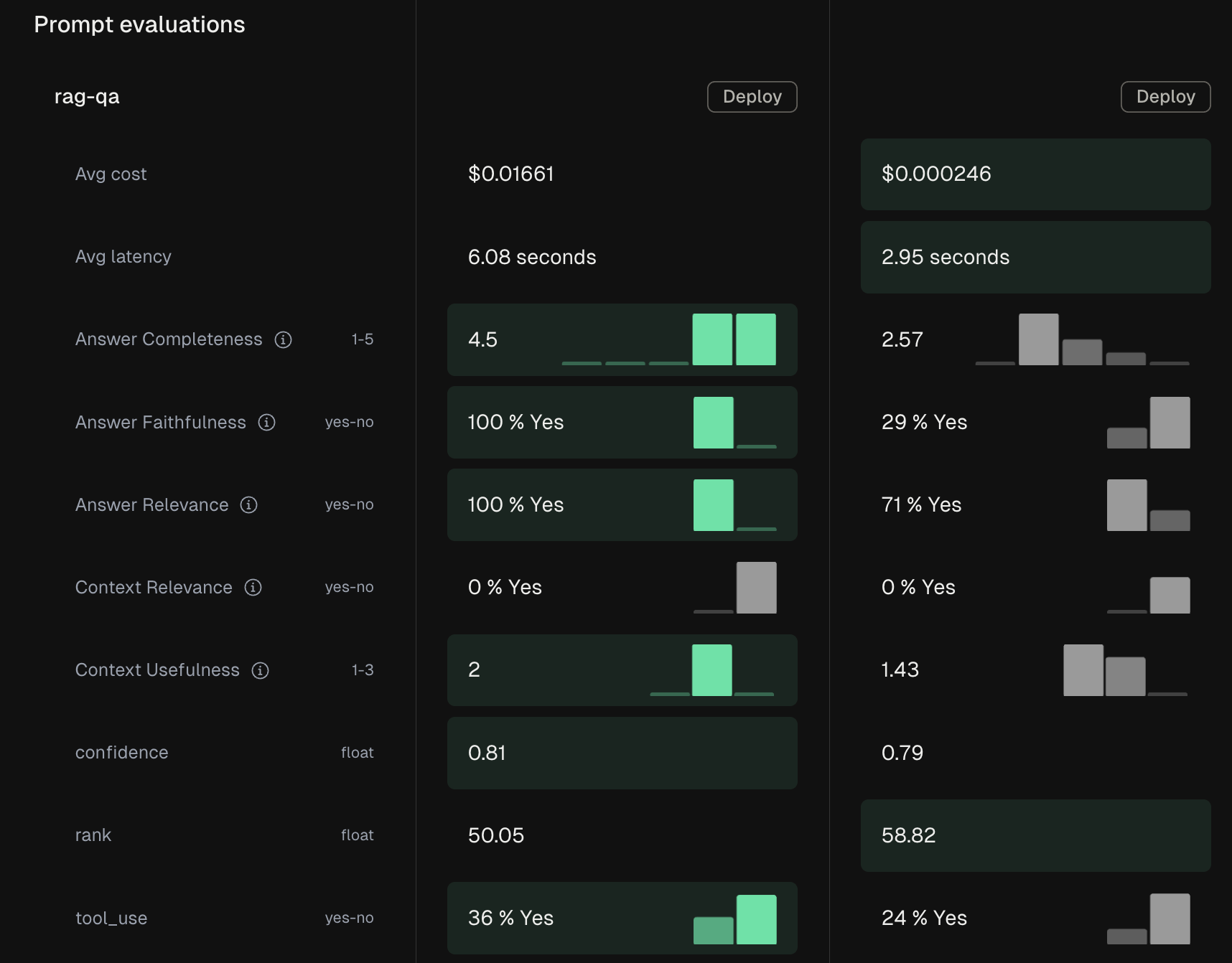
Component tests excel at prompt optimization, model comparisons, parameter tuning, and enabling non-technical team members to participate in the testing process.
Learn more about Component Testing →Core Concepts
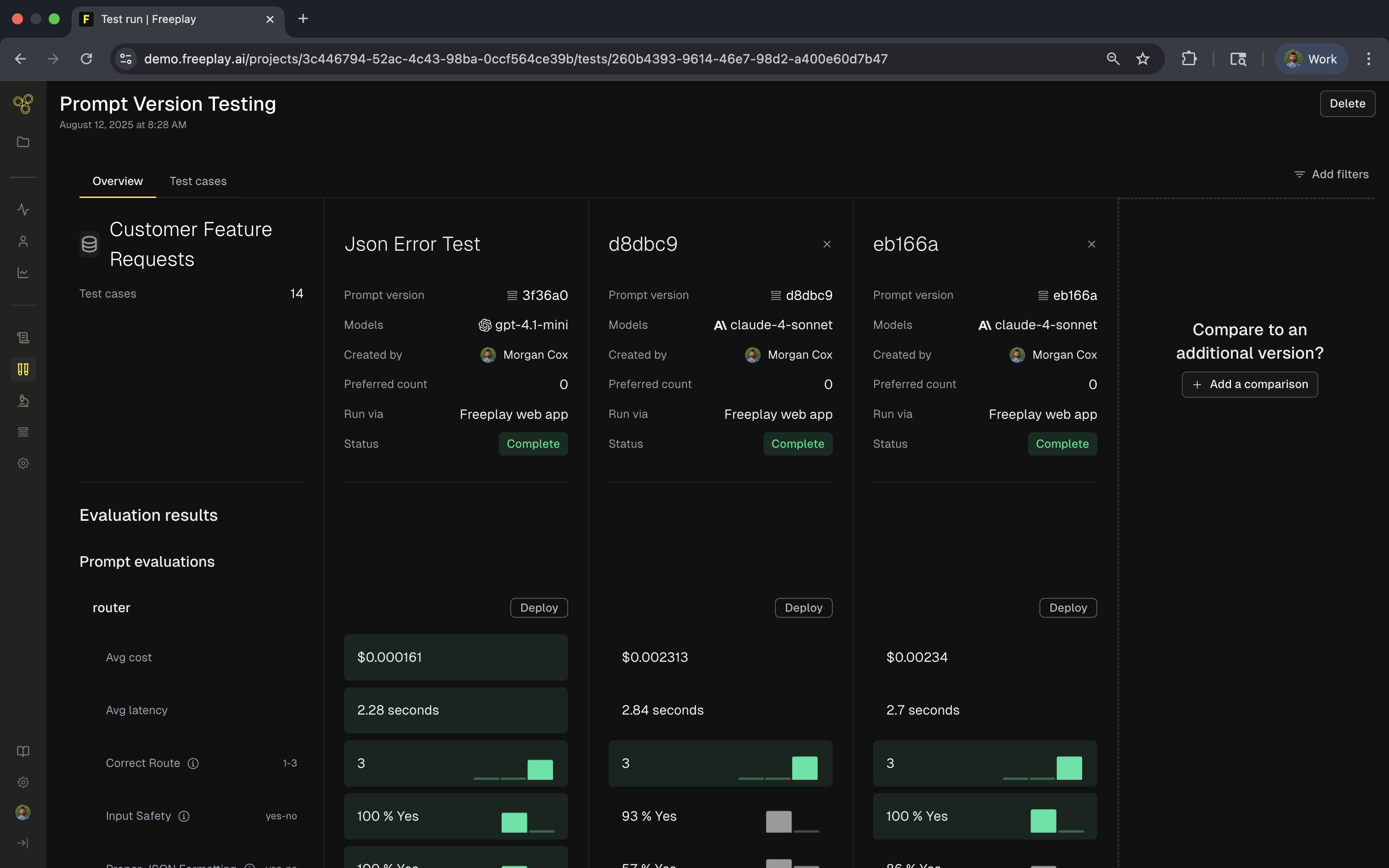
A Test Run evaluates your LLM pipeline against a dataset to measure performance. Each run processes your test cases through the pipeline, applies evaluations, and provides both aggregate and row-level insights. The foundation of any test is your dataset—a curated collection of scenarios that represent important use cases, edge conditions, and known failure modes.
Test Runs integrate with Freeplay's evaluation system, applying model-graded evals, code-based checks, and human review to assess quality. You can compare results across different versions, models, or time periods to track improvements and catch regressions.
When to Use Each Approach
The choice between end-to-end and component testing depends on what you're trying to validate. Use end-to-end testing when deploying to production, making system architecture changes, or validating agent behavior with tool usage. These comprehensive tests ensure no system-wide regressions slip through.
Component testing shines during prompt development, model selection, and quick validation checks. The UI-based testing makes it accessible to product managers and domain experts who need to review outputs without writing code.
Getting Started
For developers, begin by installing the Freeplay SDK and creating datasets from your production data. Set up both end-to-end and component tests as part of your development workflow, integrating them into your CI/CD pipeline for automated validation.
Product teams can jump straight into the Freeplay UI to create test datasets from important use cases and run component tests on prompt changes. The visual interface makes it easy to review results and provide feedback without technical expertise.
Updated 3 days ago
Now that you're armed with the ability to test your models, let's move onto Datasets.