
Model-Graded Evaluations
Model-graded Evaluations
Model-graded auto-evaluations on the Freeplay platform are performed in two capacities:
- Batch testing via Test Runs
- Test Runs allow you to proactively run batch tests against Datasets to measure your system performance over time and compare changes side by side. These Test Runs can be executed either via the UI or via the SDK.
- Live Monitoring of Production Sessions
- Freeplay will automatically sample a subset of your production traffic and run auto evaluations on them to give you insight into how your systems are behaving in the wild.
Configuring Model-graded Evaluations in Freeplay
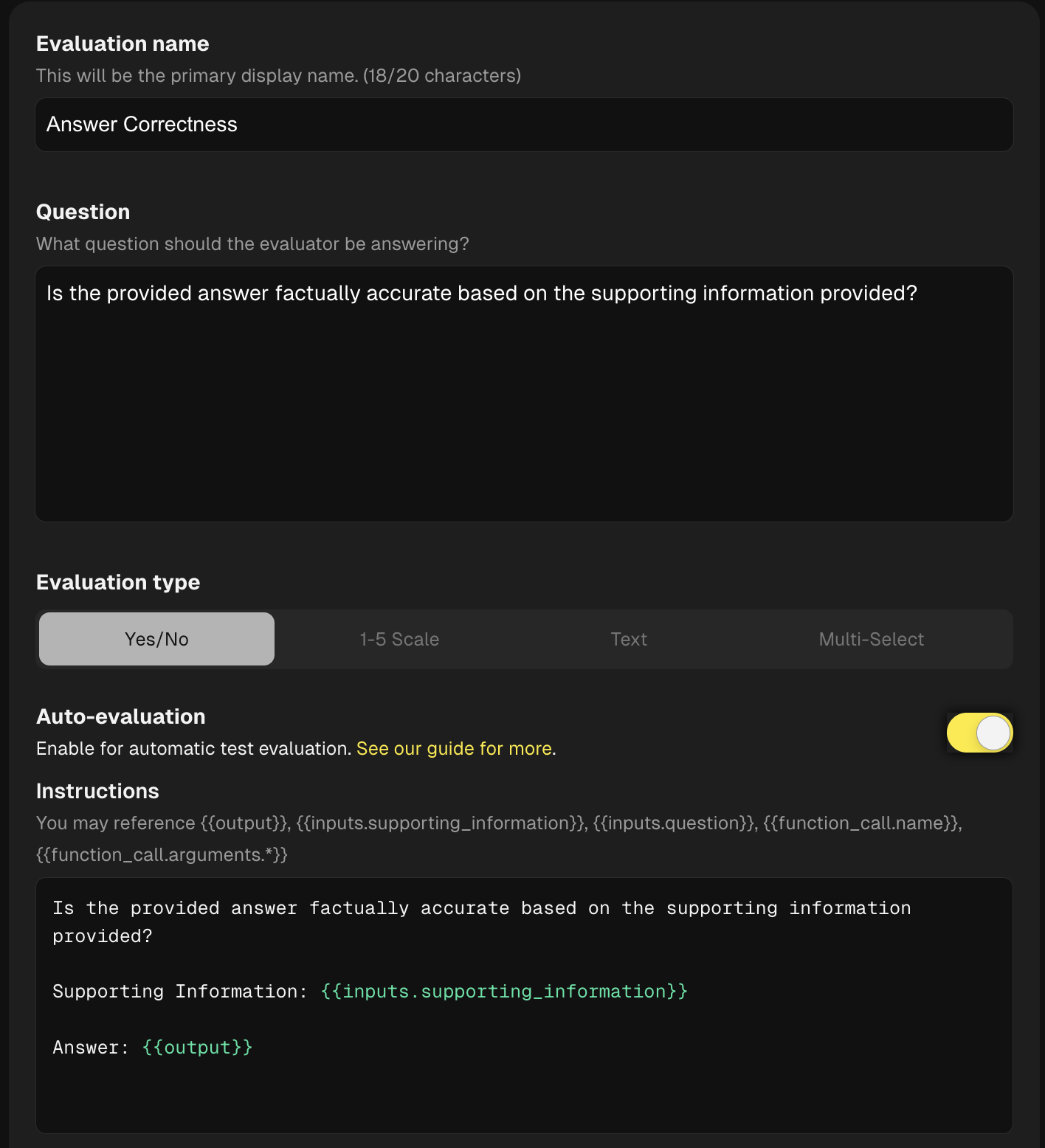
You'll start by configuring evaluation criteria on a prompt template. Go to Prompts > Pick the prompt you want > scroll to the Evaluations section at the bottom.
Each evaluation criteria requires the following components:
-
Name: Give the criteria an easy-to-recognize name that will show up in the UI for your team.
-
Question: Along with the name, define the guiding question that a human evaluator should address for that criteria. This question should be clear and focused, with a goal to make sure each evaluator understands objectively how to answer the question.
-
Evaluation Type: Freeplay currently supports 4 types of evaluation criteria:
- Yes/No boolean (use "Yes" as the positive value)
- 1-5 Scale (use "5" as the positive value)
- Text (free text string, useful for leaving comments or other descriptions of issues)
- Multi-select (tags/enums, useful for data categorization)
-
Optionally: Enable model-graded auto-evaluation: Choose whether you want to configure and run an auto-evaluator for the criteria. More details on setting up model-graded auto-evaluators below.
- Enter a prompt in the "Instructions" section. This is where you detail to the LLM what it is evaluating and importantly indicate which parts of the prompt or output you want to target. This is what dictates the values passed to the LLM at execution time.
- You can target components of your prompt with mustache syntax. In this case we will use
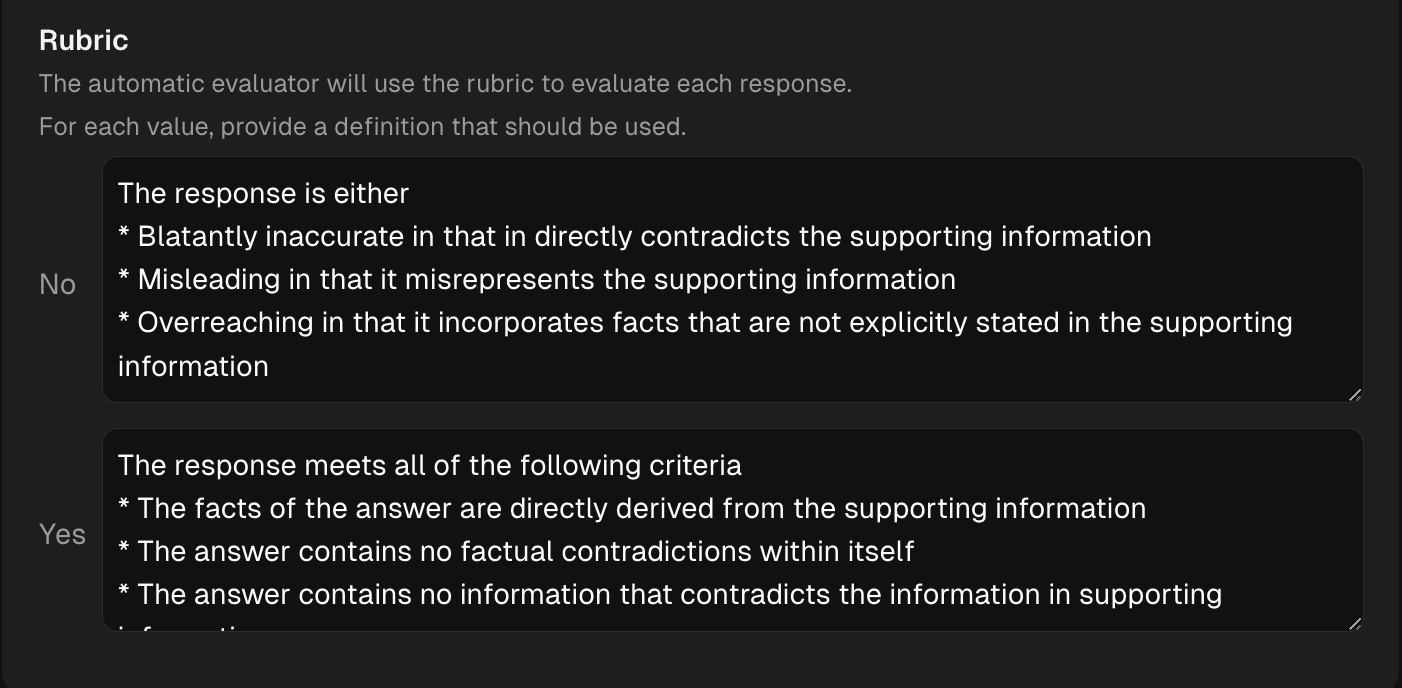
{{inputs.supporting_information}}to target out retrieved context and{{output}}to target the LLM generated output which are the two components we need for this eval. - Next configure a Rubric, this section details the criteria the LLM will use to make it's final decision and can be extremely valuable for generating high quality responses
- You can target components of your prompt with mustache syntax. In this case we will use
- Enter a prompt in the "Instructions" section. This is where you detail to the LLM what it is evaluating and importantly indicate which parts of the prompt or output you want to target. This is what dictates the values passed to the LLM at execution time.
- Next configure a Rubric, this section details the criteria the LLM will use to make it's final decision and can be extremely valuable for generating high quality response.
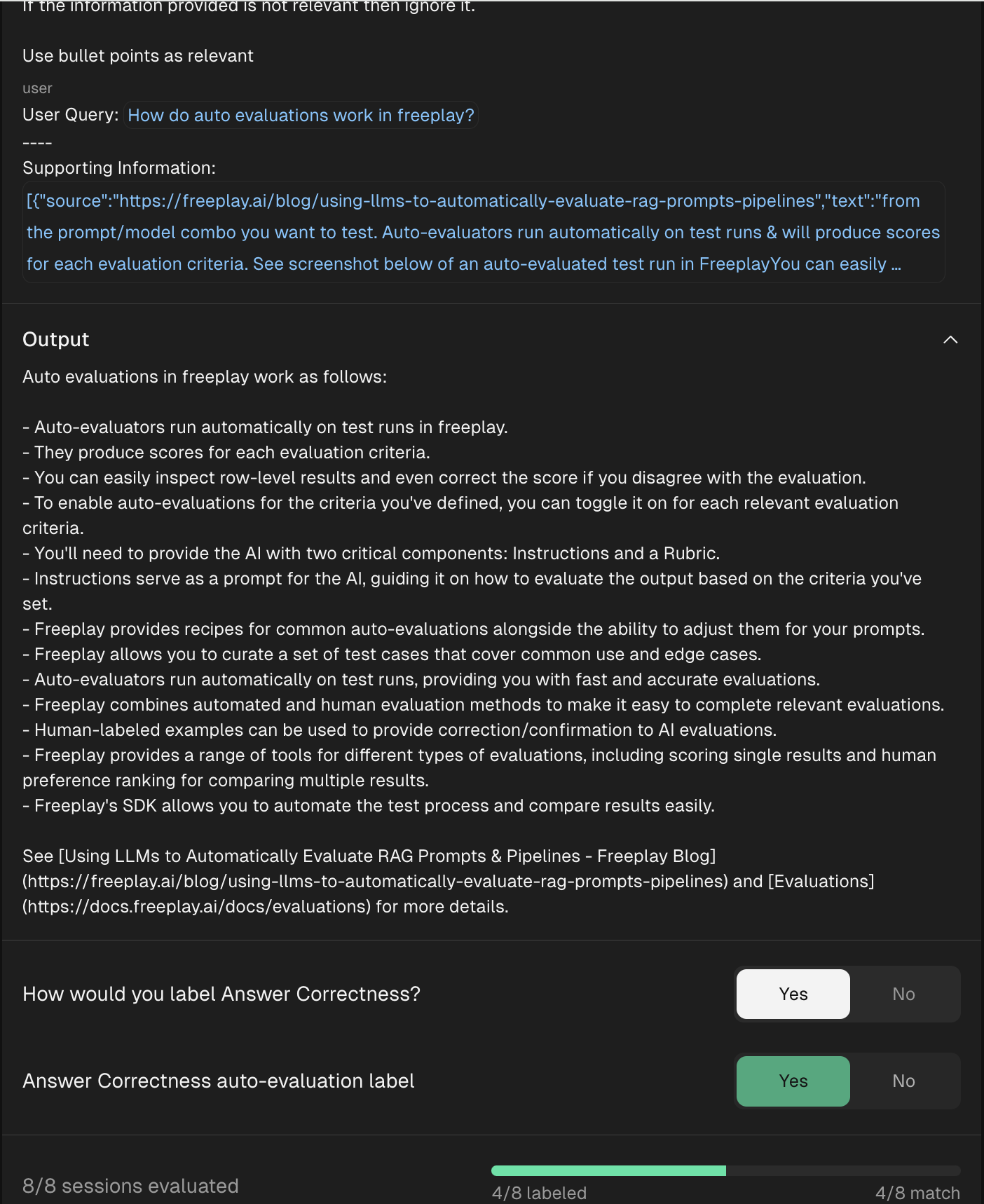
- Optionally: Align your Auto-evaluators
Prompts for auto-evaluators can take some iteration to get right, just like with other prompt engineering. Freeplay provides functionality to align your Auto Evaluators with human feedback from your team as you're creating your eval criteria. Each time you update the prompt, you can re-run it against a sample of examples and compare to your team's choices.
Updated 12 days ago
Now review each evaluation type and then move onto test runs once all your evaluations are configured!