- Completions: Atomic LLM calls made up of a prompt and a response or output from a model.
- Traces: Optionally used to group related completions, e.g. when multiple completions are used to generate chat turn or single agent flow
- Sessions: The container for all completions and traces that make up a customer interaction. These can be 1:1 with completions for a simple feature that just uses one prompt, or they can be very large at times e.g. an entire conversation thread between a single user and a chatbot over multiple hours.
Completions
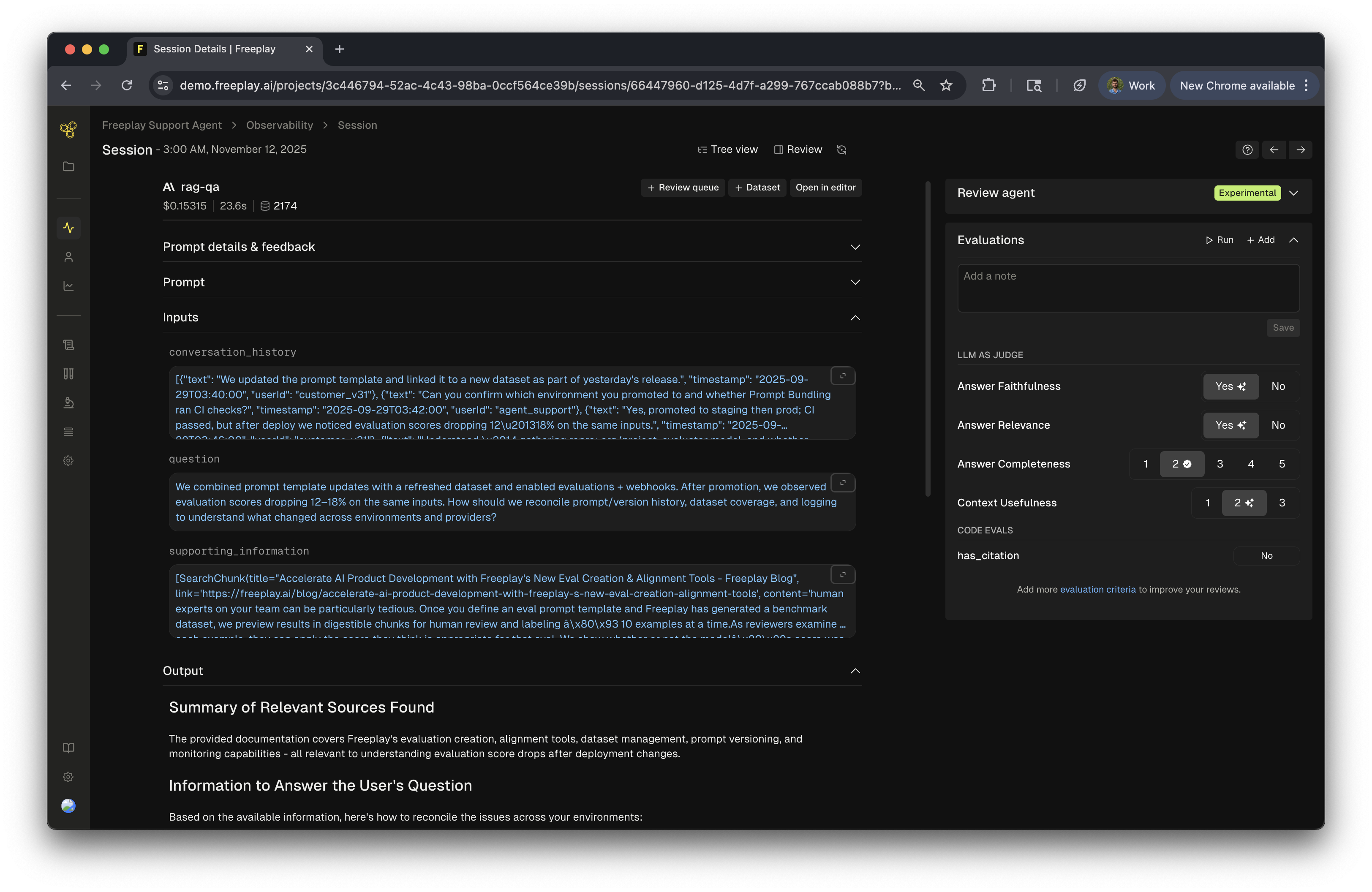
Traces
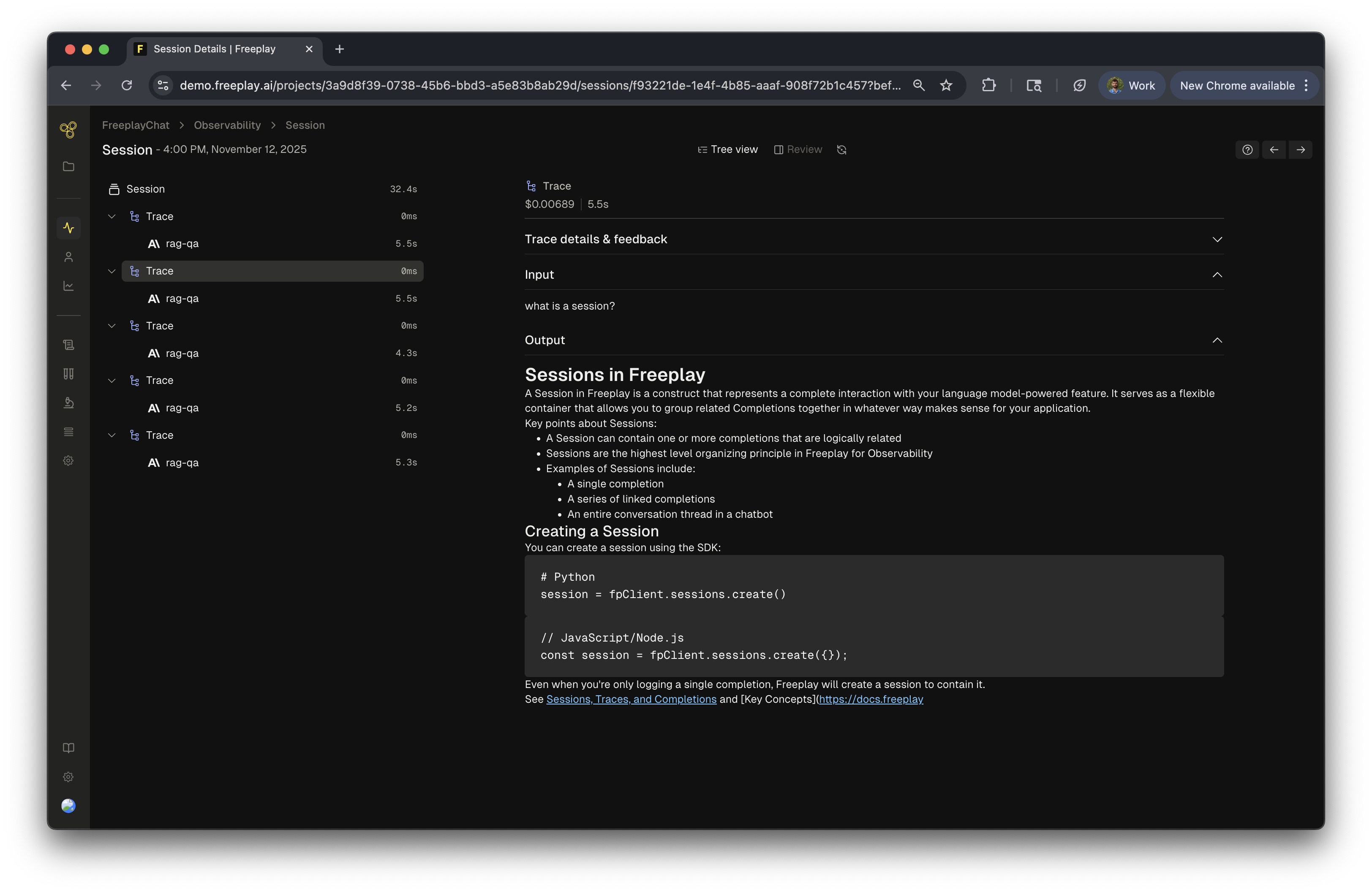
While all completions must be tied to a session, traces are entirely optional. You do not need to use them if they don’t make sense in the context of your application logic.
input_question and output_answer to render the start and end of a chat turn between a user and a bot. Traces must be used to take advantage of this feature.
Sessions
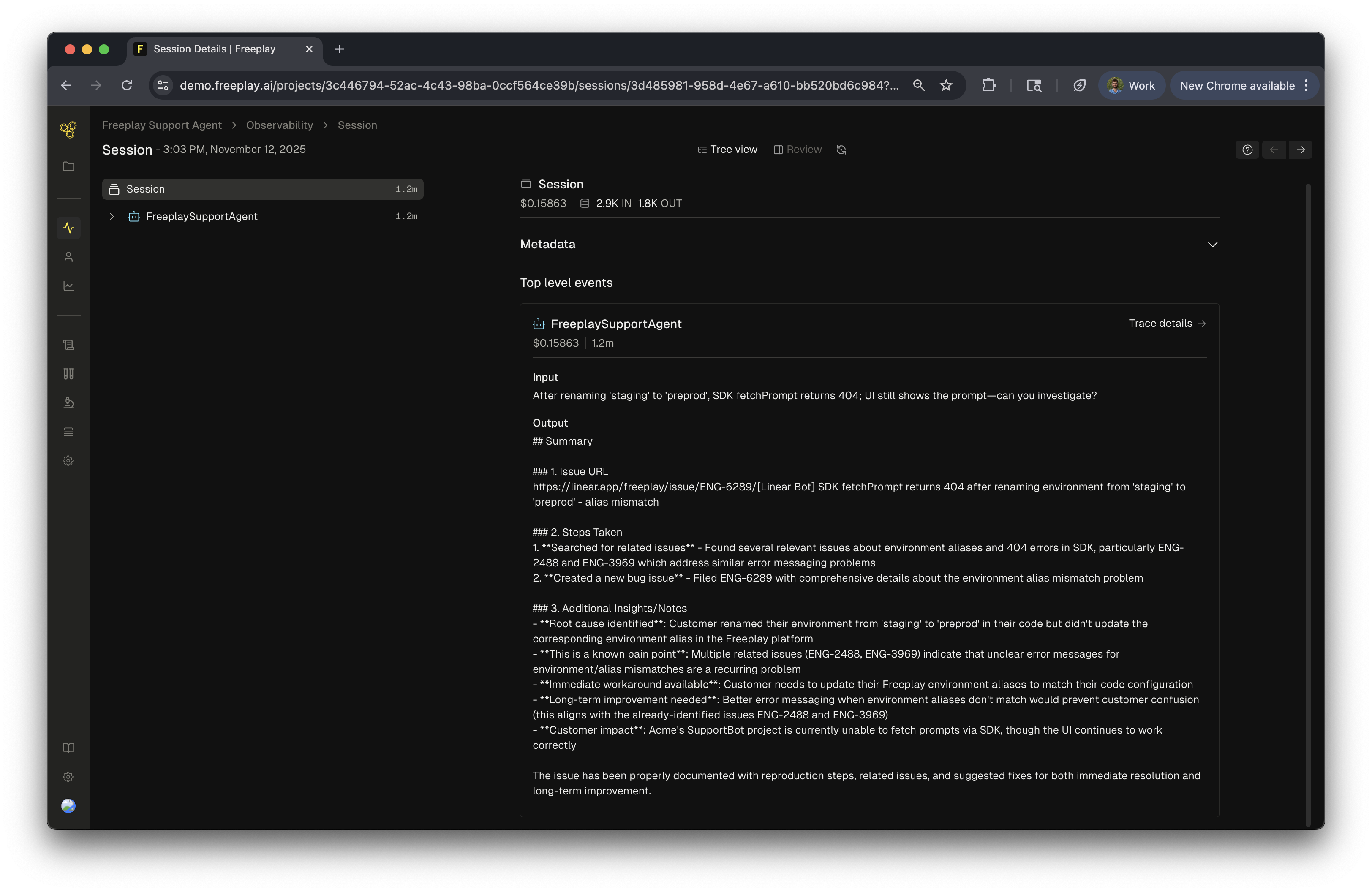
Sessions View
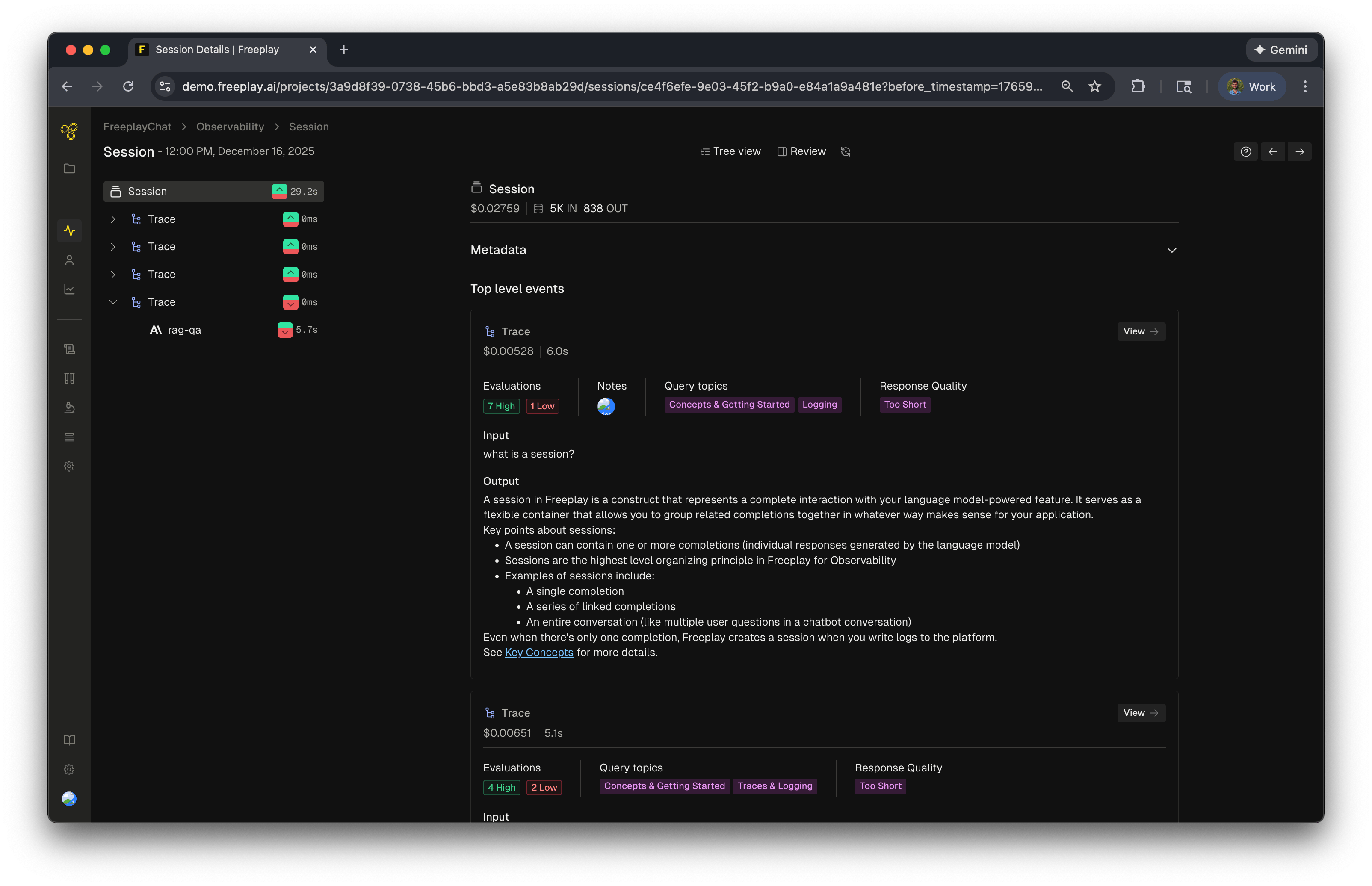
- Left sidebar navigation displays the hierarchical structure of your session, showing multiple traces with color-coded indicators that reveal evaluation performance at a glance (green for passing, red for failing evaluations)
- Top-level session metrics show aggregated information including total cost ($0.002759), token usage (5K input, 838 output), and overall evaluation results
- Individual trace details present evaluation breakdowns (e.g., “7 High, 1 Low”), associated notes, query topics, and response quality assessments for each interaction in the conversation
- Full context display shows the complete input and output for each trace, making it easy to understand what the user asked and how the system responded
API Reference: Key endpoints for working with observability data:
- Completions: Record Completion, Search Completions
- Traces: Record Trace, Search Traces
- Sessions: List Sessions, Search Sessions
What’s next
Now that you understand how to build Sessions and Traces with Completions, explore these resources:- Multi-Turn Chatbot Support - Implement conversation tracking
- Agents - Structure complex agent workflows
- Glossary - Definitions of key Freeplay terms