Step 1: Create a Dataset for Benchmarking
Having a labeled Dataset to test prompt, model, and pipeline changes against is critical for building a repeatable and robust LLM development process. This is also an important foundational component when configuring a fallback LLM provider Freeplay provides in app functionality for you to label and curate dataset from real production sessions.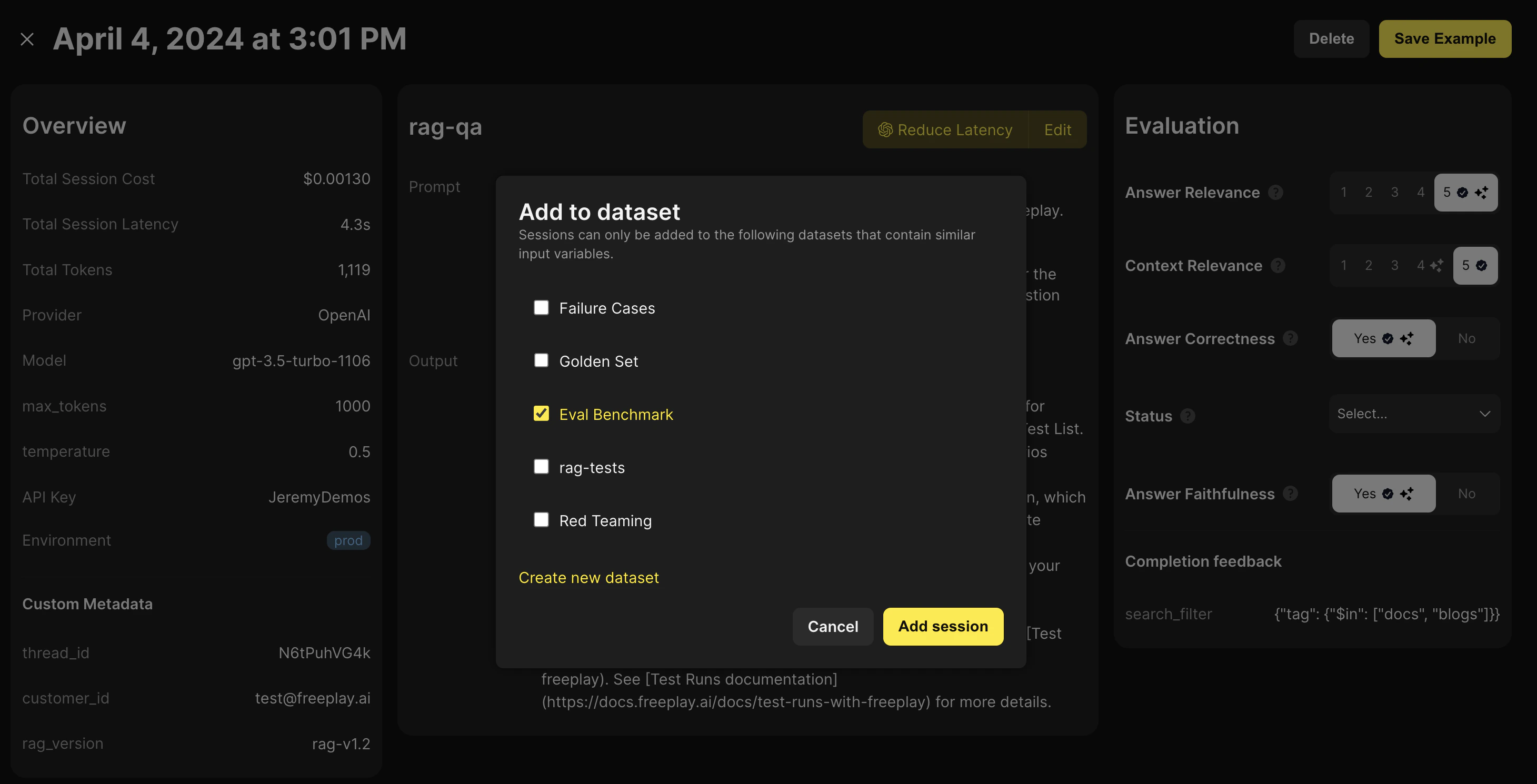
Step 2: Configure a Prompt Template and Model Config for your Fallback Provider
Freeplay’s prompt editor is an interactive playground allowing you to load in data from your datasets and compare prompt versions side by side. Here we have our primary provider prompt pulled up and as we iterate on a prompt for Anthropic’s Sonnet model. We’ve loaded in a few examples from our benchmark dataset to test against.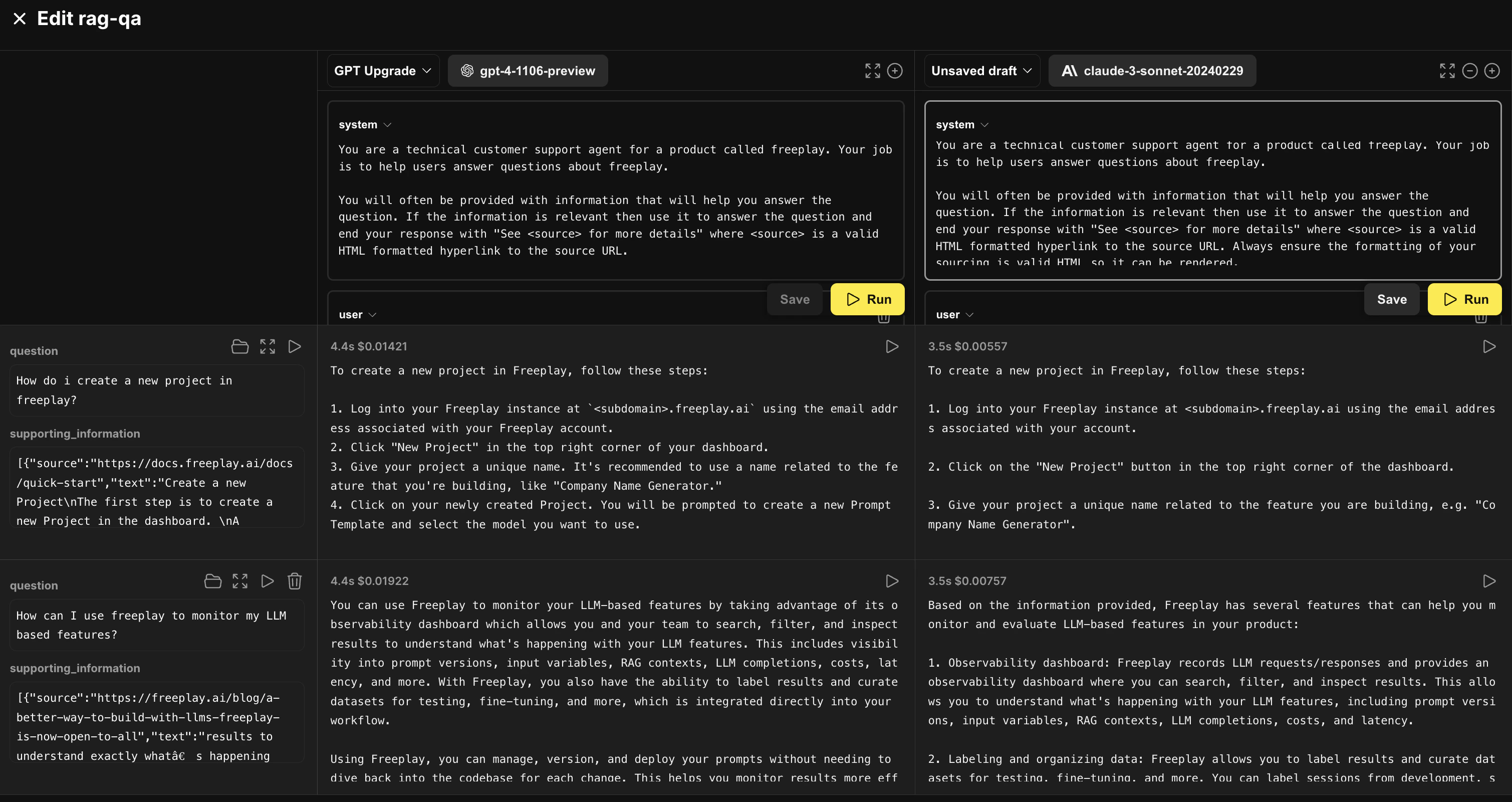
Step 3: Test your Fallback Provider at Scale
After we’ve created a fallback provider prompt template that seems to work well, we want to test it at scale and compare it to our benchmark dataset, which in this case was generated by our primary provider and human labeled. We can kick off the test run either in app from Freeplay or in code via the Freeplay SDK.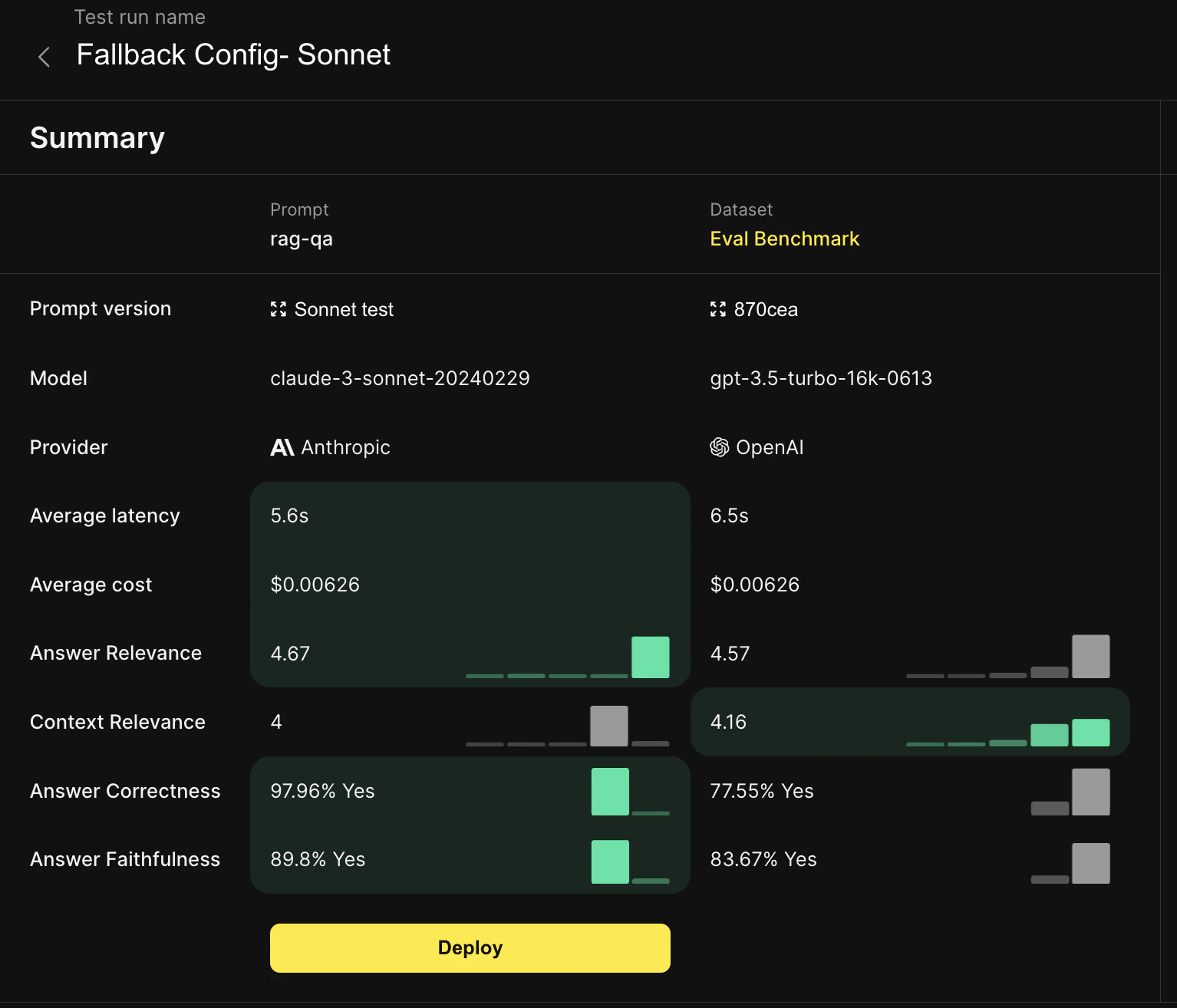
Step 4: Deploy your Fallback Provider and Configure your Application Code Accordingly
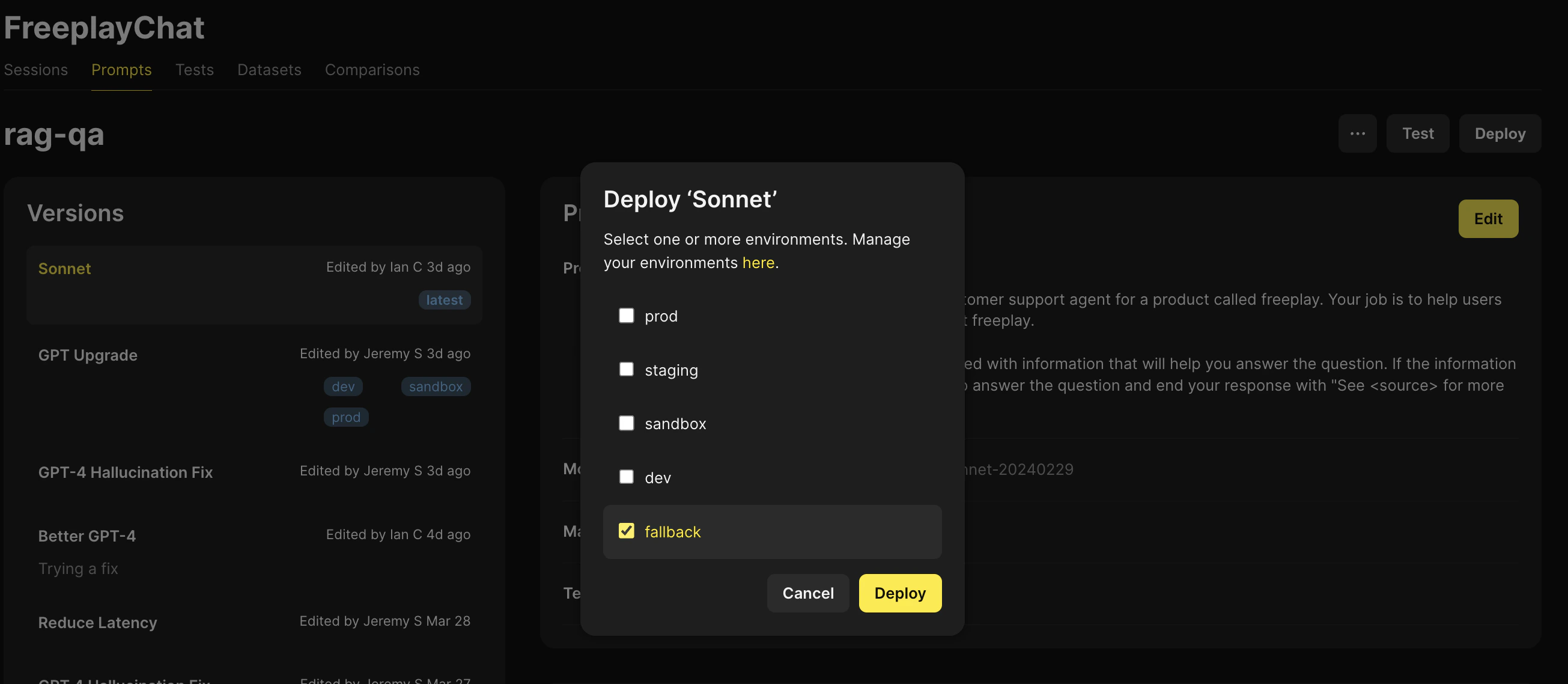
- Using the prompt template from our primary provider we try making a request
- If the request fails, we fetch the prompt template for our secondary provider from Freeplay and make a request
- Record the results back to Freeplay