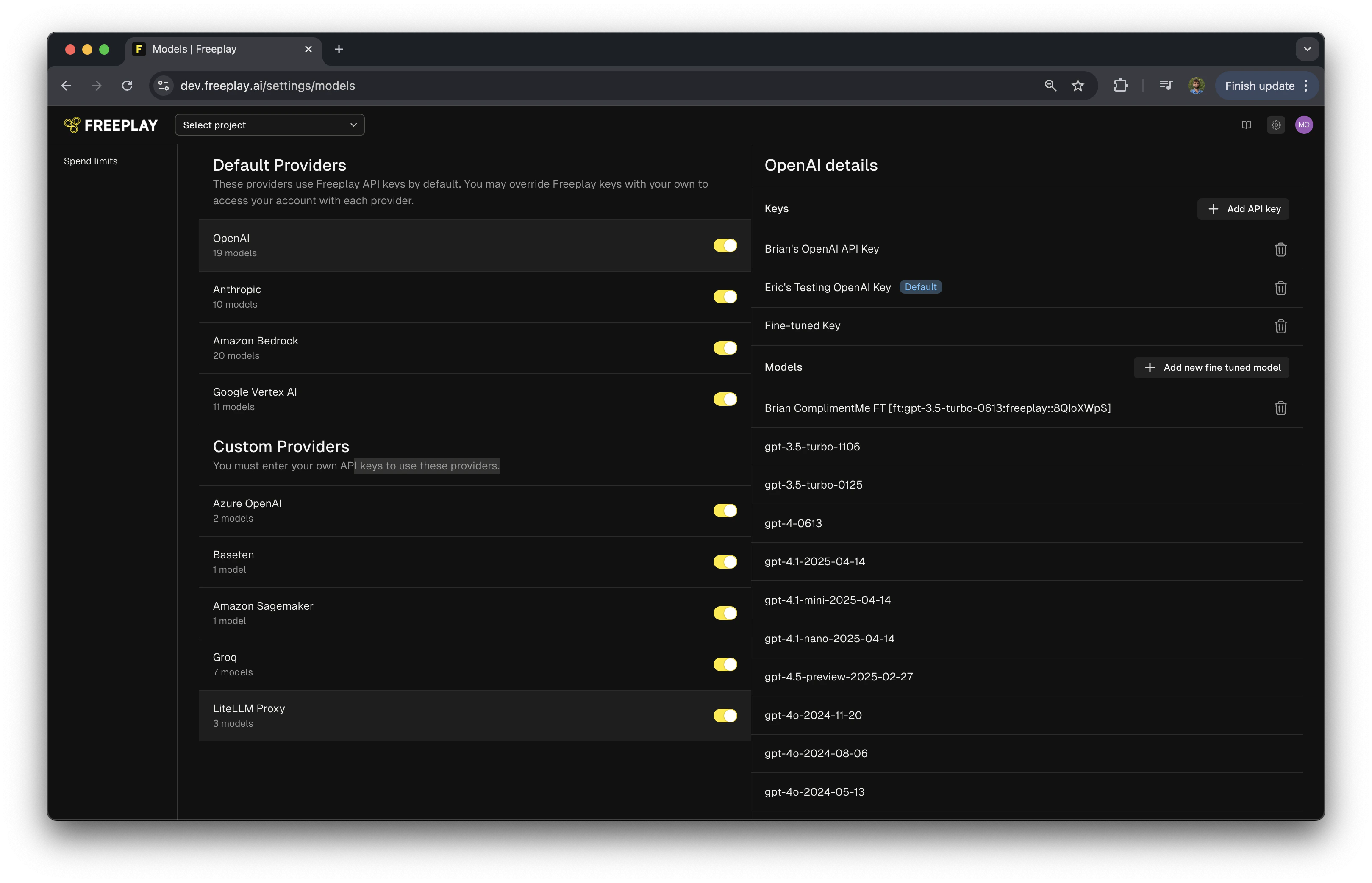
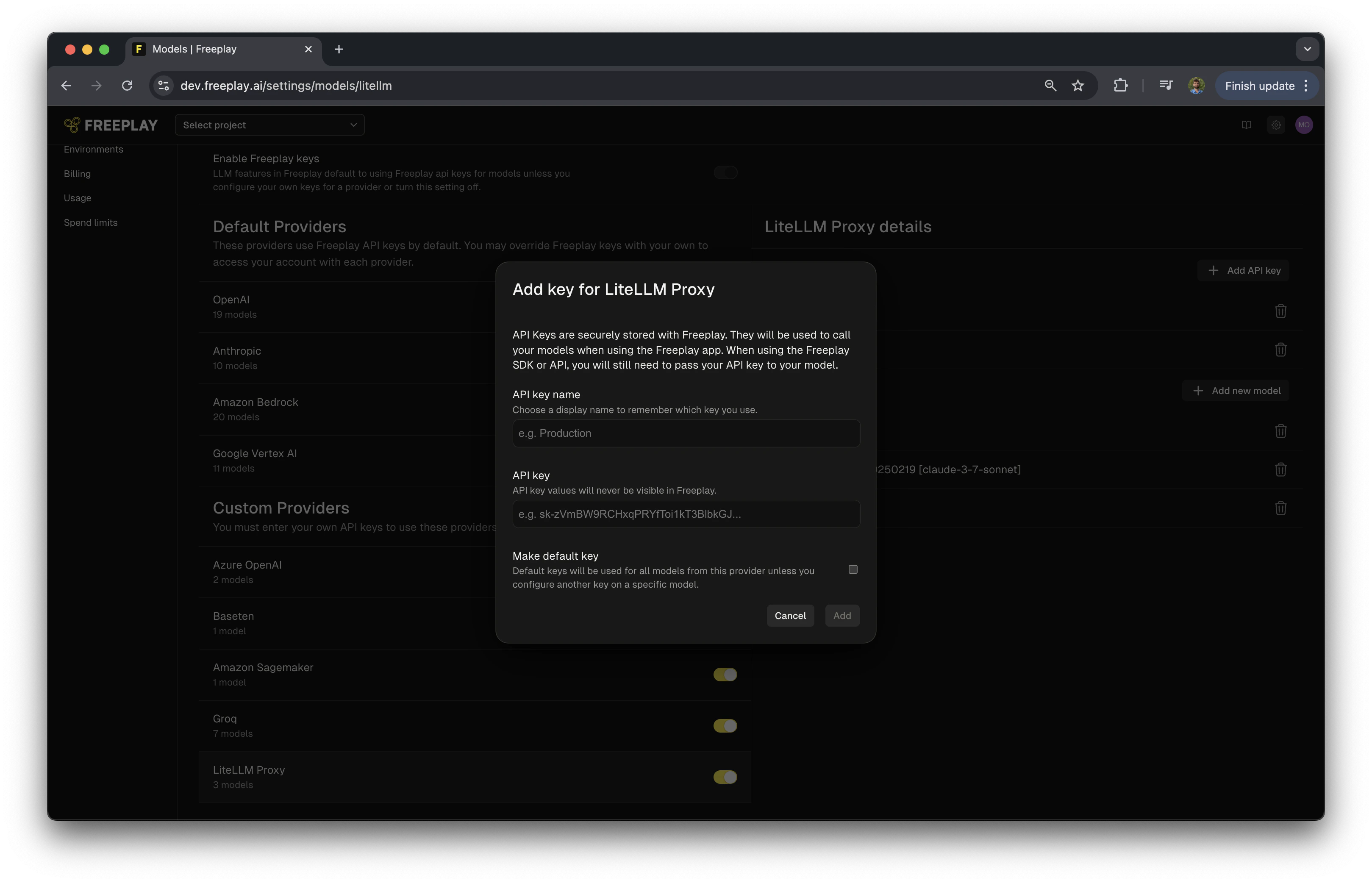
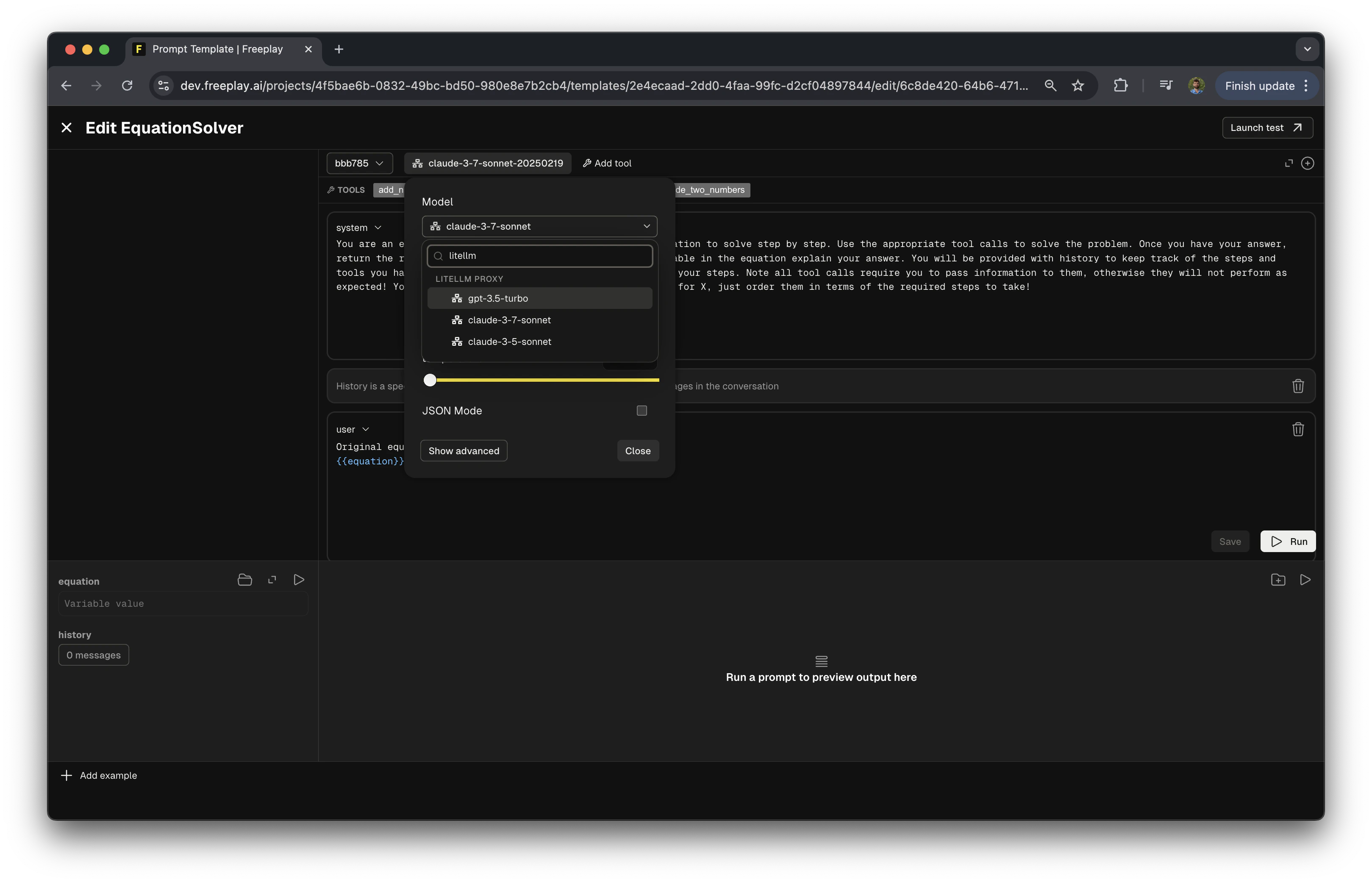
#######################
## Configure Clients ##
#######################
# Configure the Freeplay Client
fp_client = Freeplay(
freeplay_api_key=API_KEY,
api_base=f"{API_URL}"
)
# Call OpenAI using the LiteLLM url and api_key.
# This handles the routing to your models while keeping the response
# in a standard format.
client = OpenAI(
api_key=userdata.get("LITE_LLM_MASTER_KEY"),
base_url=userdata.get("LITE_LLM_BASE_URL")
)
#####################
## Call and Record
#####################
# Get the prompt from Freeplay
formatted_prompt = fp_client.prompts.get_formatted(
project_id=PROJECT_ID,
template_name=prompt_name,
environment=env,
variables=prompt_vars,
history=history
)
# Call the LLM with the fetched prompt and details
start = time.time()
completion = client.chat.completions.create(
messages=formatted_prompt.llm_prompt,
model=formatted_prompt.prompt_info.model,
tools=formatted_prompt.tool_schema,
**formatted_prompt.prompt_info.model_parameters
)
# Extract data from LiteLLM response
completion_message = completion.choices[0].message
tool_calls = completion_message.tool_calls
text_content = completion_message.content
finish_reason = completion.choices[0].finish_reason
end = time.time()
print("LLM response: ", completion)
# Record to Freeplay
## First, store the message data in a Freeplay format
updated_messages = formatted_prompt.all_messages(completion_message)
## Now, record the data directly to Freeplay
completion_log = fp_client.recordings.create(
RecordPayload(
project_id=PROJECT_ID,
all_messages=updated_messages,
inputs=prompt_vars,
session_version_info=session,
trace_info=trace,
prompt_info=formatted_prompt.prompt_info, # Note: you must pass UsageTokens for the cost calculation to function
call_info=
CallInfo.from_prompt_info(formatted_prompt.prompt_info, start, end,
UsageTokens(completion.usage.prompt_tokens, completion.usage.completion_tokens))
)
)