
9/3/24 Updates
Recent Updates: Easier Model-Graded Evals, New Ground Truth Comparison Support, More Granular Filtering, Expanded API Capabilities, and Major Model Updates
- Create and align model-graded evals within Freeplay
- Target ground truth values for evals in the Freeplay UI
- Filter for individual Completions instead of just complete Sessions
- Use the Freeplay API to filter, export or delete Sessions, and manage Datasets
- Try the new Gemini 1.5 Pro experimental release, and make sure to stop using old GPT-3.5 versions by next week
Over the last month we’ve rolled out significant updates that make it easier than ever to create, tune, and deploy model-graded evaluations so that they align with expectations for human experts. This workflow is critical to building model-graded evals you can trust.
We’ve also made it easier to compare test outputs with ground truth values, made it easier to filter & review individual completions separately from full multi-prompt sessions, and expanded API capabilities including for exporting session/log data, and managing datasets. Finally, some important model updates at the bottom!
Updated Eval Alignment Flow
We've made a significant update to our model-graded eval “alignment workflow,” making it much easier to create, tune, and deploy model-graded evaluations. Now, anyone on a product development team can seamlessly spot issues, create new evals, test them with real data to confirm the results align with human judgment, and deploy them for production monitoring or offline tests.
You can choose any OpenAI or Anthropic model for your model-graded evals (with more model support coming soon!). We also now display LLM reasoning in the app so it’s even easier to see what’s happening.
Dive deeper with this blog post and demo video
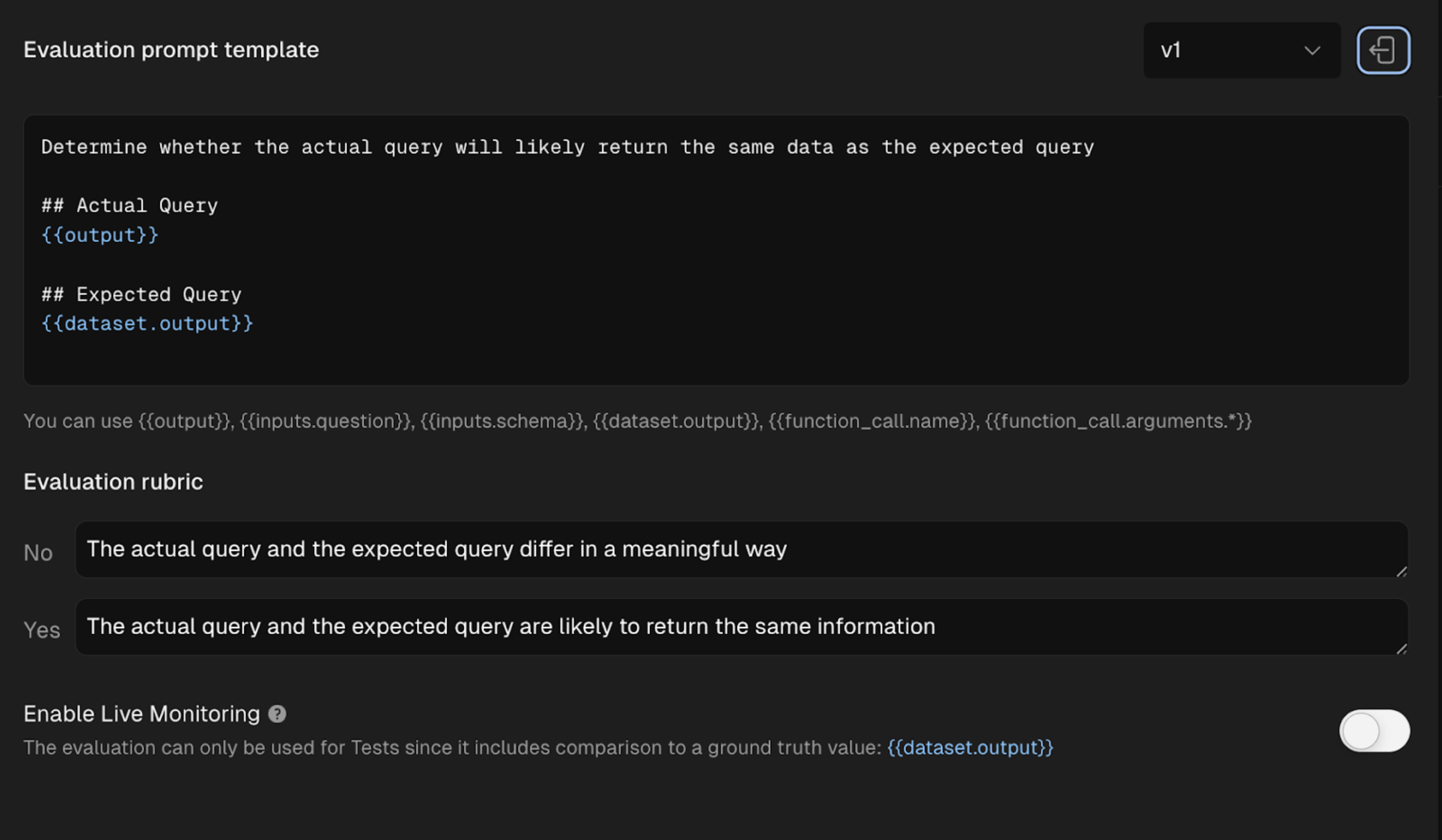
Target Ground Truth Values in Evals
We've made it easier to compare test outputs to ground truth dataset values when using model-graded evals. Before this was possible in our SDK only. Now it’s easy to do when configuring model-graded evals in the Freeplay app too. This makes it easier to create auto-evals that compare new results to a ground truth value from your datasets, ensuring you can accurately track whether your models are regressing or improving relative to previous results. Simply use {{dataset.output}} when writing auto-eval prompts.
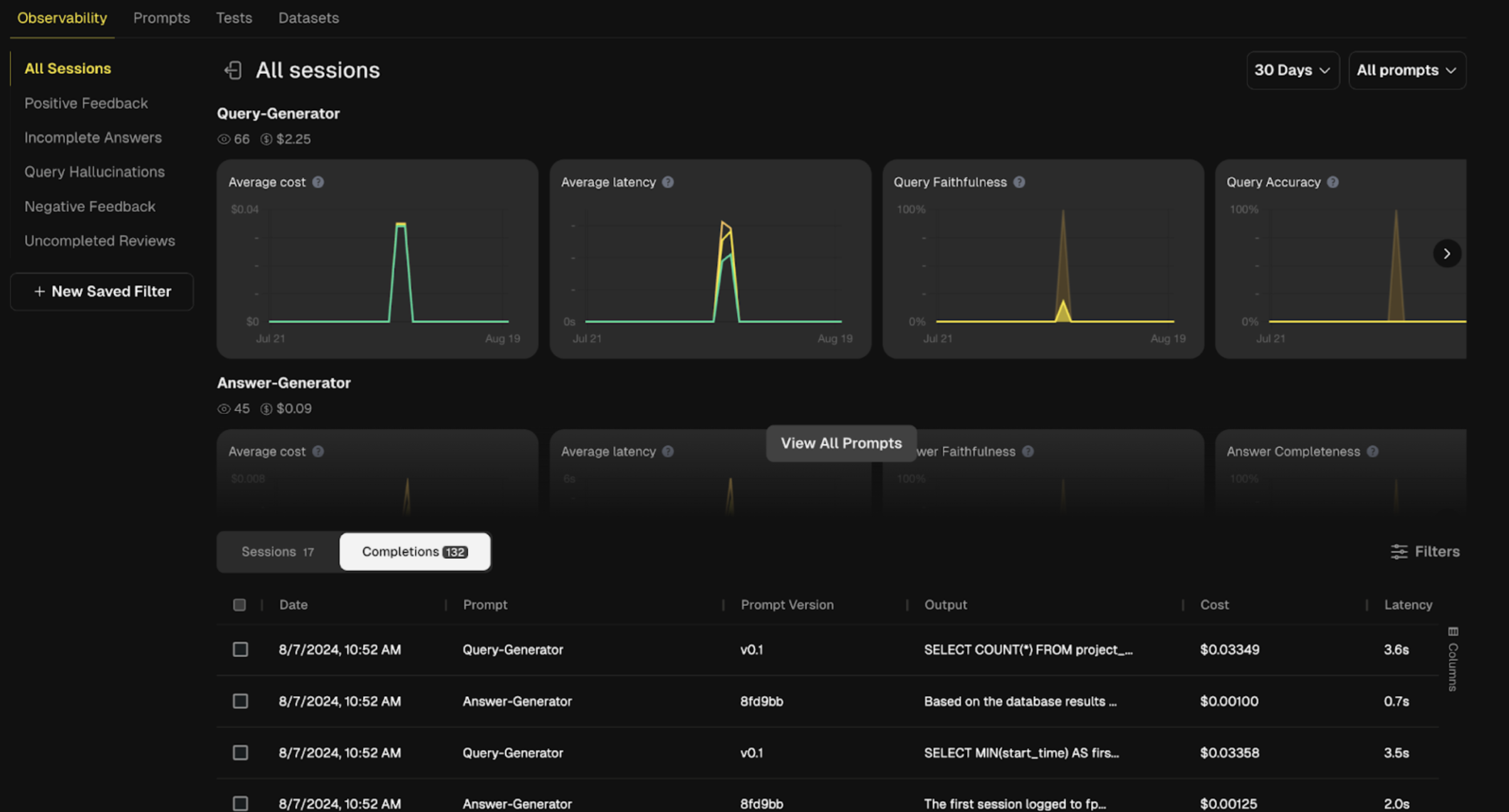
Filter for Individual Completions
We've introduced a new “Completions” tab on the Observability page, giving users a more granular view of completion data. Now, you can filter and drill down either at the “Session” level (for a whole group of Completions), or directly at the individual “Completion” level — making it faster and easier to find the specific insights you need. For instance, in a Project with multiple prompt templates, this means it easier to look at results from a single prompt template.
Expanded API Capabilities
We continue to invest in our APIs adding new functionality including the ability to:
- Filter and export Sessions
- Delete Session (e.g. for compliance purposes)
- Manage datasets
Additionally, we've standardized and improved error documentation so it’s easier to manage errors in your code.
These updates make it easier to integrate Freeplay with downstream reporting systems, and to maintain data synchronization across platforms.
Check out the latest API docs here.
Model Updates: Gemini 1.5 Experimental is here! And GPT-3.5 versions going away
The new Gemini 1.5 Pro "experimental" release (version 0801) launched as #1 on the lmsys leaderboard. Try it now in Freeplay.
Also, if you're still using any GPT-3.5 versions older than 1106, they will be deprecated by OpenAI on September 13. Please update them to version 1106, or even better, gpt-4o-mini.