
5/24/24 Updates
Recent Updates: Code-Driven Evals, Model-Graded Eval Alignment, Saved Filters for Faster Reviews, Updated Comparisons Feature, and Full Support for Enterprise Models
- Log eval results directly from your code, including pairwise comparisons against ground truth datasets
- Align your model-graded evals to your team’s expectations with human feedback
- Saved Filters make it faster to review production data on a regular basis
- Updated comparisons workflow for streamlined comparisons between different prompts, models, or versions of your code
- Use your enterprise models like Bedrock Anthropic, Azure OpenAI, or Llama 3 on SageMaker in the Freeplay playground and Tests features
Lots of big updates this month! All of these make it faster to test, evaluate and iterate on generative AI systems in production.
Expanded Evaluations: Log Evals From Your Code, Including Pairwise Comparisons on Tests
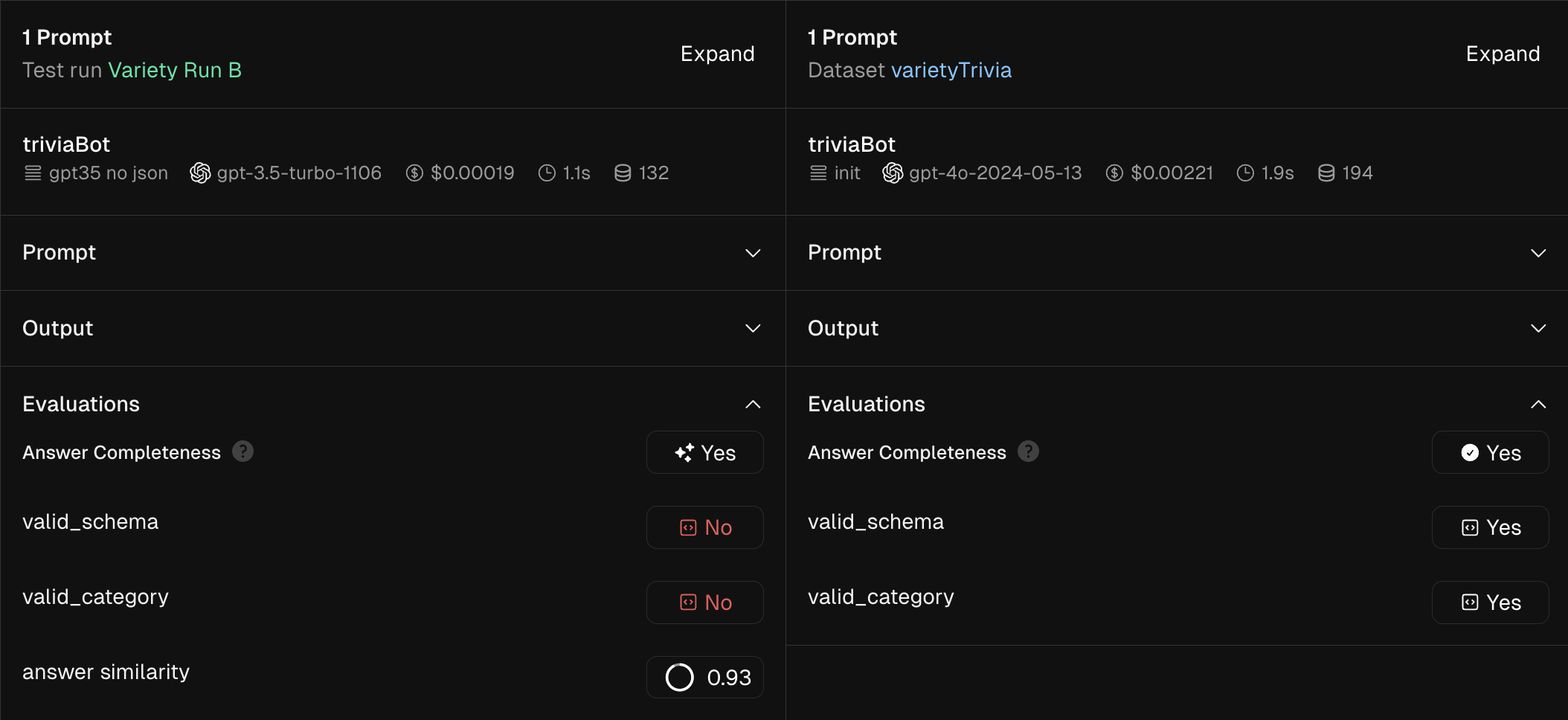
Freeplay’s evaluation functionality to date has been oriented around human and model-graded evals, but often they’re not the only types of evals you want to run on production or test data. A full production eval suite often includes code-driven checks for things like format or schema adherence, or pairwise string comparisons against ground truth examples (in the case of testing). These are all now possible using Freeplay, so you can combine human review, model-graded evals, and code-driven evals seamlessly.
Our SDKs now support logging code-driven evaluations with any completion — whether on live data, or in a test scenario. This is particularly useful for evaluations requiring logical expressions through code, such as JSON schema checks or category assertions, and for pairwise comparisons on a test run to evaluate things like embedding distance between two strings.
More details here and an SDK implementation example is here. You can also check out this quick Loom for a walk through.
Screenshot below of JSON schema and category checks failing on a test
Improve Human Alignment for Model-graded Evals
Model-graded evals are invaluable when evaluations require nuanced judgment, but like any LLM-driven system they require some iteration to get right. Freeplay has long made it easy to confirm or correct any model-graded scores directly in the app.
We recently launched an interactive alignment interface for you to align your model-graded evals with human judgment before deploying them. The interface is designed to ensure that your evaluations are as reliable and accurate as possible, giving you a trustworthy suite of tools for assessing quality. As your collection of human-labeled ground truth examples grows, it becomes even faster to iterate on model-graded evals and confirm they'll match your team's expectations in production.
Check out the Loom below to see how it works.
Saved Filters for Streamlined Review Workflows
The most successful AI teams spend lots of time looking at real-world data to spot issues and find opportunities for optimization.
With Saved Filters, you can easily create and save persistent groups of Sessions that match criteria you’re interested in for review, such as hallucinations, negative customer feedback, or poor retrievals. Once set up, these filters automatically generate a queue you can return to for focused review, enabling your team to efficiently manage and prioritize issues that require attention.
Here’s another quick demo.
Comparisons View Now Integrated into Tests
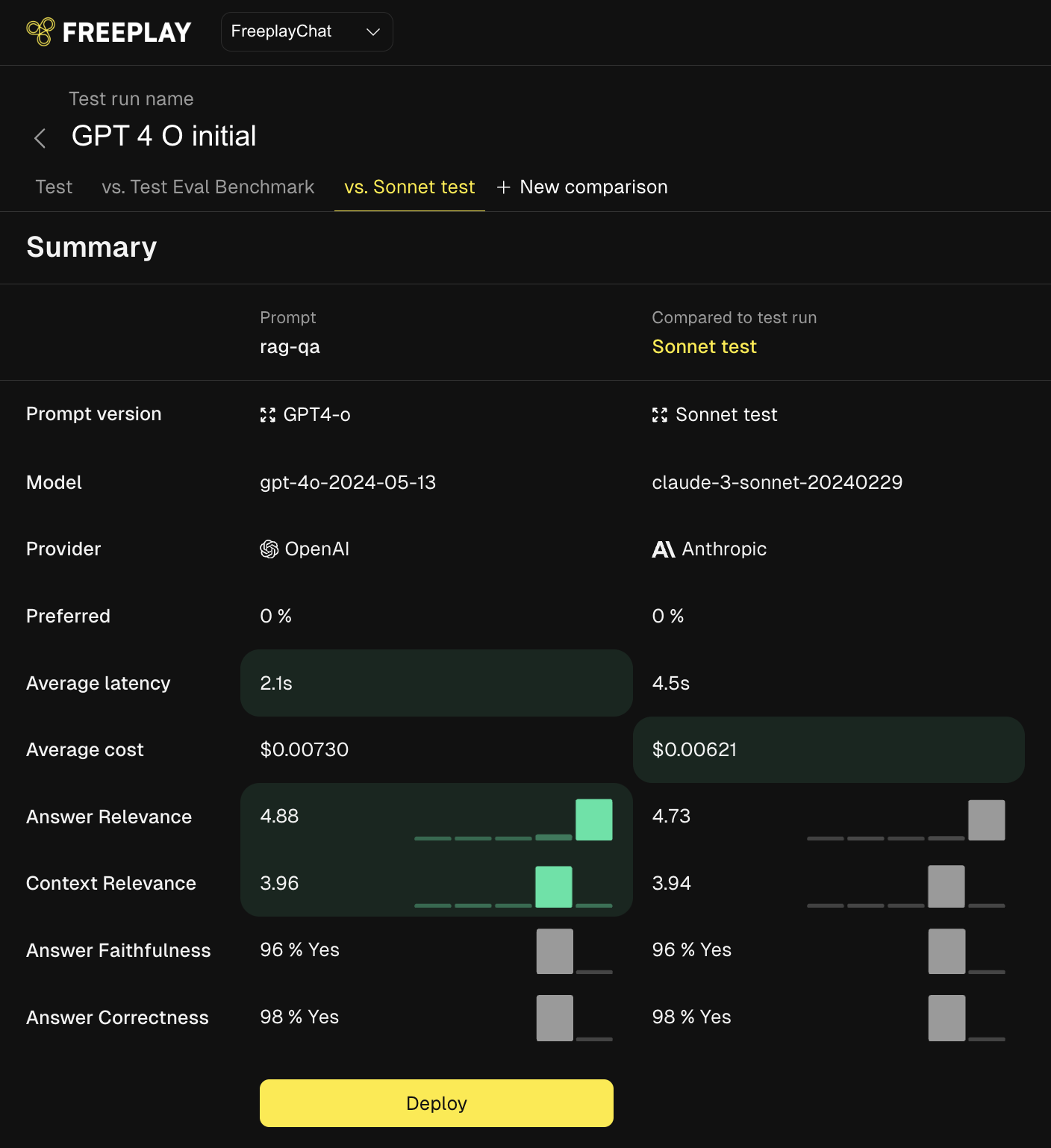
Freeplay’s Comparisons feature made it easy to review test results against a ground truth, or two test versions side by side. It also made it easy to capture human preference between the two, for times when eval metrics aren’t enough to make a choice.
We've now integrated the Comparisons workflow directly into our batch Tests feature, so you can quickly launch as many Comparisons as you want after running a new test. This makes it much faster to evaluate how changes in models and prompts perform against each other in a head-to-head setup.
Check out how it works in this demo video.
New Models: Call your Bedrock, Sagemaker and Azure models from the Playground using your own API keys or IAM role assumption. Plus, GPT-4o support!
We’ve added full in-app support for Bedrock Anthropic, Sagemaker Llama 3, and Azure OpenAI allowing you to fully use your privately-hosted endpoints in the Freeplay playground and with in-app batch Tests. See directions for configuring your custom models here.